Story
Capturing Individual Human Preferences with Reward Features
Key takeaway
Researchers developed a way to model each person's unique preferences in AI systems, which could lead to more personalized and effective technologies.
Quick Explainer
The Reward Feature Model (RFM) provides a principled approach for learning reward functions that can adapt to individual user preferences. The key idea is to represent the reward as a linear combination of learned "reward features" that capture different aspects of the user's preferences. This allows RFM to be quickly adapted to new users by learning the coefficients of this linear combination, rather than retraining the entire model. The authors show that this adaptive capability makes RFM more robust to heterogeneous user preferences compared to non-adaptive baselines, and allows it to outperform other adaptive methods, including those using large language models.
Deep Dive
Capturing Individual Human Preferences with Reward Features
Overview
This paper formalizes and analyzes the problem of learning a reward model that can adapt to individual user preferences. The authors propose the Reward Feature Model (RFM), an architecture specifically designed for fast adaptation to new users. RFM can be trained using pairwise response comparisons provided by humans, learning a set of reward features that can be linearly combined to represent a user's preferences, even if their preferences are not reflected in the training data.
Methodology
- Problem Formulation: The authors formalize the problem of learning a reward model that can adapt to individual user preferences through the lens of empirical risk minimization. They define a distribution
Dover users, contexts, responses, and preferences. - Theoretical Analysis: The authors derive a PAC bound showing how the approximation error depends on the number of training examples and raters. They analyze the trade-offs involved in the collection of preference data and the use of an adaptive reward model.
- Reward Feature Model (RFM): The authors propose the RFM architecture, where the reward function is expressed as a linear combination of learned reward features. RFM can be quickly adapted to new users by learning the coefficients of this linear combination.
- Training and Adaptation: The authors describe how RFM can be trained using pairwise preference data and then adapted to new users by learning the linear combination coefficients.
Data & Experimental Setup
The authors conduct experiments using the UltraFeedback dataset, a large dataset of pairwise preferences. They define a synthetic user population with 13 preference features, allowing them to control the homogeneity of user preferences.
Results
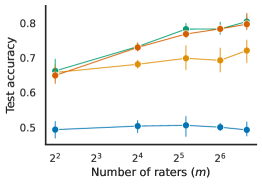
- The authors show that RFM's performance improves with the number of training raters, as predicted by their theoretical analysis.
- RFM is more robust to heterogeneous user preferences compared to a non-adaptive baseline.
- RFM can be quickly adapted to new users using as few as 30 pairwise preference examples.
- RFM outperforms several adaptive counterparts, including linear and non-linear baselines, as well as in-context adaptation methods using large language models.
Limitations & Uncertainties
- The authors note an inherent tension between the simplicity of RFM's adaptation and the complexity of its training.
- The authors' synthetic user population may not fully capture the nuances of real-world user preferences.
What Comes Next
- Exploring ways to further improve the training of RFM, building on the insights provided by Shenfeld et al. and Bose et al.
- Applying RFM to other modalities beyond language, such as images, sound, and video.
- Investigating the use of RFM as a reward function in reinforcement learning settings with multi-step interactions.