Story
TokaMind: A Multi-Modal Transformer Foundation Model for Tokamak Plasma Dynamics
Key takeaway
Researchers have developed TokaMind, a machine learning model that can better simulate the complex dynamics of nuclear fusion reactors, which could help improve the efficiency of future fusion power plants.
Quick Explainer
TokaMind is a multi-modal transformer-based foundation model that aims to address the challenges of tokamak plasma modeling. It ingests heterogeneous signals from tokamak diagnostics, representing them as a sequence of embedded tokens. The transformer-based model then processes this token sequence, with modality-specific output heads enabling flexible adaptation to diverse downstream reconstruction and forecasting tasks. By pretraining on a broad mixture of tokamak data and fine-tuning selectively, TokaMind demonstrates improved performance over CNN baselines, especially on challenging high-frequency and long-horizon predictions, while also supporting efficient model scaling.
Deep Dive
Technical Deep Dive: TokaMind: A Multi-Modal Transformer Foundation Model for Tokamak Plasma Dynamics
Overview
TokaMind is an open-source foundation model framework for fusion plasma modeling, based on a Multi-Modal Transformer (MMT) and trained on heterogeneous tokamak diagnostics from the publicly available MAST dataset. It supports multiple data modalities (time-series, 2D profiles, and videos) with different sampling rates, robust missing-signal handling, and efficient task adaptation via selectively loading and freezing model components.
Problem & Context
Achieving reliable, high-performance operation of tokamak fusion reactors depends on accurate reconstruction and forecasting of plasma behavior, which underpins monitoring and control across operating regimes. However, tokamak data presents several key challenges:
- Strongly-coupled, nonlinear plasma dynamics produce heterogeneous signals spanning multiple modalities and time scales.
- The plasma state must be inferred from indirect and noisy measurements, making reconstruction and forecasting intrinsically challenging.
- Experimental datasets often include missing channels and dropouts, posing a practical challenge for specialized models.
- Existing machine learning approaches are often limited to narrow objectives, input/output schemas, and operating regimes.
To address these constraints, TokaMind adopts a foundation model approach, pretraining a Multi-Modal Transformer on broad, heterogeneous tokamak data to enable efficient adaptation to diverse downstream tasks and changing signal schemas.
Methodology
Data Summary
TokaMind uses the publicly available MAST tokamak dataset, which includes a range of diagnostic measurements (magnetic, radiative, kinetic), actuator commands, and derived equilibrium quantities. The signals span different modalities (time-series, profiles, videos) and sampling frequencies (0.2 kHz to 500 kHz).
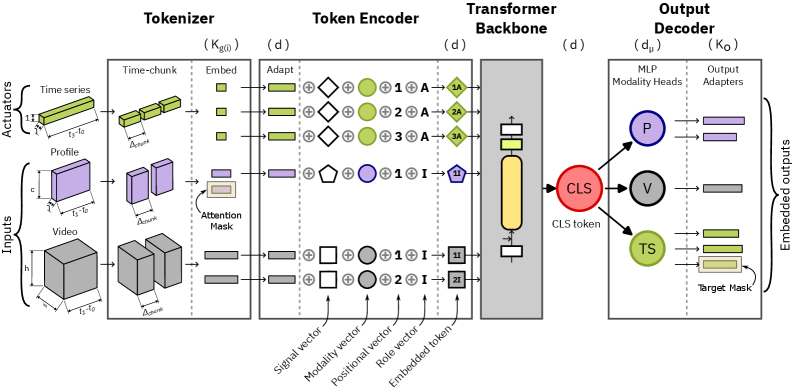
Tokenization and Embedding
The first step is tokenization, which converts the windowed multi-modal signals into a variable-length set of token embeddings:
- Chunking: Each input/actuator signal is decomposed into fixed-duration chunks, with chunks filtered for validity.
- Embedding: Chunk and window embeddings are generated using a signal-specific codec, with the default being a training-free Discrete Cosine Transform (DCT3D) codec.
Model Architecture
The tokenized inputs are processed by a Transformer-based model with three main components:
- Token Encoder: Maps each token to a shared embedding space, adding learned metadata embeddings.
- Transformer Backbone: Applies masked self-attention over the token sequence.
- Output Decoder: Consists of modality-specific heads and per-target output adapters, enabling flexible prediction across tasks.
Training and Adaptation
TokaMind is first pretrained on a broad mixture of tokamak signals and tasks, then fine-tuned for specific downstream objectives. The framework supports efficient adaptation through warm-starting and selective freezing of model components.
Results
TokaMind consistently outperforms a CNN baseline across the standardized MAST benchmark, which covers a range of reconstruction and forecasting tasks. Key findings:
- Fine-tuning from the pretrained checkpoint generally performs better than training from scratch, especially on the most challenging long-horizon and high-frequency tasks.
- A smaller "Tiny" model variant retains most of the performance gains of the larger "Base" model, demonstrating efficient representation learning.
- DCT3D embeddings perform competitively with learned VAE embeddings on the Group 1 tasks, suggesting the simple frequency-based representation is already effective for these signals and horizons.
Limitations & Uncertainties
- Task 4-5, which involves forecasting high-frequency (50 kHz) magnetic signals, remains the most challenging scenario, with model performance limited by heavy-tailed errors in rare regimes or outlier windows.
- While DCT3D embeddings work well overall, further investigation is needed to understand the trade-offs between learned and frequency-based representations, especially for high-frequency content.
What Comes Next
Future work will focus on:
- Extending TokaMind beyond the MAST dataset to other tokamaks and reactor settings, enabling broader cross-device generalization.
- Investigating more advanced embedding choices, including task-adaptive representations, to further improve performance, particularly for high-frequency targets.
- Integrating pretrained PDE foundation models as physics-aware priors to enhance data efficiency and long-horizon forecasting.
- Applying the proposed tokenization framework to other multi-channel scientific problems with heterogeneous sensors, missing channels, and varying schemas.