Story
When to Trust the Cheap Check: Weak and Strong Verification for Reasoning
Key takeaway
Large language models can do better reasoning by using both cheap internal checks and more thorough external verification to ensure their outputs are reliable.
Quick Explainer
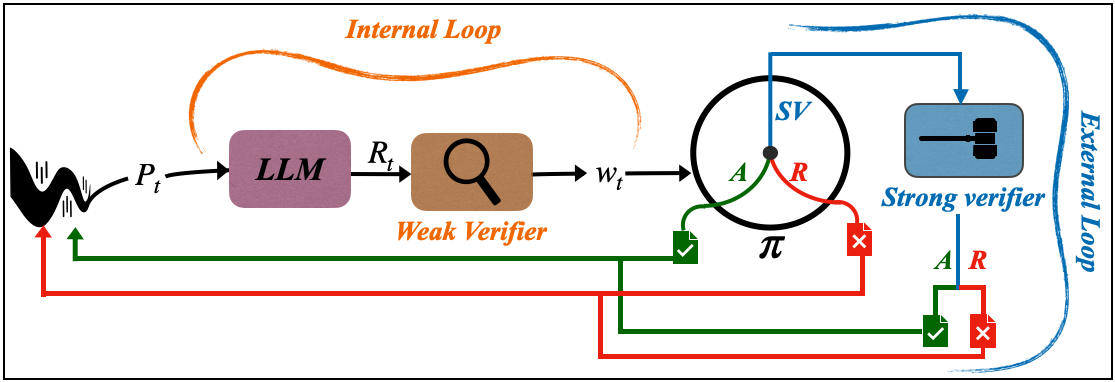
The core idea is to leverage both "weak" and "strong" verification signals when reasoning with large language models. Weak verification, such as self-consistency checks, is fast but noisy, while strong verification, like user feedback, is resource-intensive but reliable. The key is to develop optimization policies that decide when to trust the cheap weak signal versus when to invoke the more expensive strong signal. These policies follow a two-threshold structure: accept if the weak score is high, reject if it's low, and defer to strong verification if uncertain. This allows capturing the reliability of strong verification while deploying it sparingly, improving the overall efficiency of the reasoning process.
Deep Dive
When to Trust the Cheap Check: Weak and Strong Verification for Reasoning
Problem & Context
- Reasoning with large language models (LLMs) increasingly involves a verification loop:
- Internally, LLMs use "cheap" verification signals like self-consistency or proxy rewards (weak verification)
- Externally, users inspect outputs and provide feedback (strong verification)
- Weak verification is fast and scalable but noisy, while strong verification is resource-intensive but reliable
- This creates a fundamental tension: how can we match the reliability of strong verification while deploying it sparingly?
Methodology
- Formalize weak-strong verification policies that decide when to accept/reject using just the weak signal, and when to invoke the strong signal
- Define metrics capturing errors of incorrect acceptance, incorrect rejection, and frequency of strong verification
- Characterize the optimal policies and their structure under population assumptions
- Develop an online algorithm (Selective Strong Verification, SSV) that provably controls type-I and type-II errors without assumptions on the query stream or model
Results
- Optimal policies exhibit a two-threshold structure: accept if weak score is high, reject if weak score is low, defer to strong verification if uncertain
- The effectiveness of weak verification is governed by its calibration (how well it matches the strong signal) and sharpness (how decisively it produces scores near 0 or 1)
- SSV algorithm maintains target error rates in finite samples while reducing strong verification usage by 46-65% compared to always using strong verification
Limitations & Uncertainties
- The current framework only uses the weak score to decide when to invoke strong verification; incorporating broader context could enable more efficient allocation
- The error guarantees are marginal (per-round), not joint; tighter control may require more complex calibration procedures
- Experiments focus on mathematical reasoning and sequential puzzle-solving; wider evaluation across diverse LLM applications is needed
What Comes Next
- Explore contextual weak-strong policies that condition decisions on the full prompt-response pair
- Develop joint error control techniques that balance type-I and type-II errors simultaneously
- Apply the framework to additional LLM-powered reasoning benchmarks and real-world deployment settings