Story
Articulated 3D Scene Graphs for Open-World Mobile Manipulation
Key takeaway
Robotics researchers have developed a new system that allows robots to understand how objects in a 3D environment move and interact. This enables robots to more effectively manipulate objects in complex real-world settings, which could improve their usefulness in homes and busine...
Quick Explainer
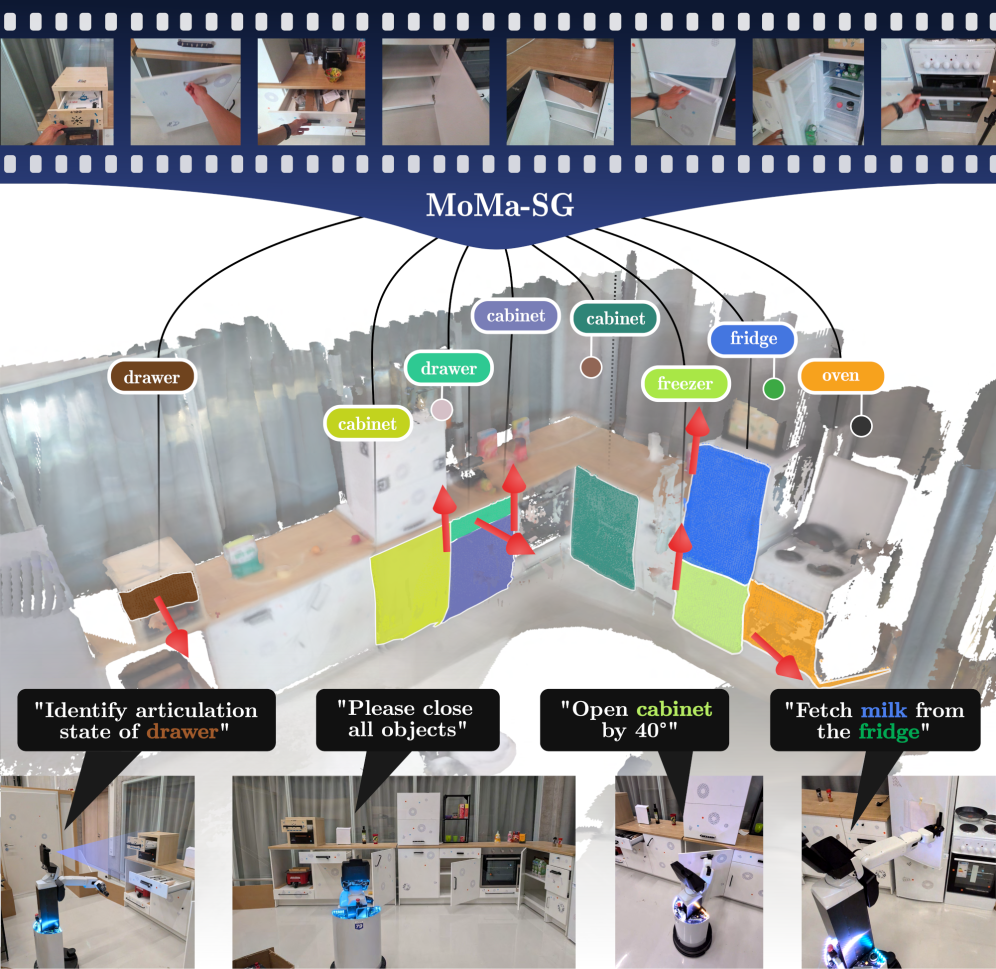
The core idea behind MoMa-SG is to build semantic-kinematic 3D scene graphs that capture the articulation and interaction capabilities of objects in complex, open-world environments. The framework combines depth-based interaction segmentation, articulation parameter estimation, and 3D scene reconstruction to construct a structured representation of how objects can move and relate to each other. This allows reasoning about the affordances and dynamics of the environment, which is crucial for enabling mobile manipulation. The novel aspects include the ability to extract articulation models (revolute, prismatic) from sparse interactions, even with occlusions and camera motion, as well as the introduction of the Arti4D-Semantic dataset to benchmark this capability in unconstrained real-world settings.
Deep Dive
Technical Deep Dive: Articulated 3D Scene Graphs for Open-World Mobile Manipulation
Overview
This technical deep dive summarizes the key contributions and findings of the paper "Articulated 3D Scene Graphs for Open-World Mobile Manipulation":
- The authors present MoMa-SG, a framework for constructing semantic-kinematic 3D scene graphs of articulated environments containing a variety of interactable objects.
- MoMa-SG can extract articulation models (revolute, prismatic) from single object interactions, even in the presence of occlusions and camera motion.
- The authors introduce the Arti4D-Semantic dataset, which combines semantic object labels, part-level articulation annotations, and contained object relationships.
- Extensive evaluations demonstrate MoMa-SG's ability to segment, estimate, and interact with articulated objects using two different robot platforms.
Problem & Context
- Traditional robotic mapping and scene understanding focus on quasi-static environments, but mobile manipulation requires understanding how objects can move and interact.
- Previous work on articulated object estimation often relies on fiducial markers, synthetic data, or constrained viewpoints, limiting real-world applicability.
- 3D scene graphs provide a structured representation for reasoning about objects and their spatial/functional relationships, but existing approaches do not model articulation.
Methodology
Interaction Discovery
- Combines an interaction prior (detected agent) and depth disparity to segment interaction intervals in RGB-D sequences.
- Applies probabilistic modeling to fuse the two signals and identify continuous interaction segments.
Articulation Estimation
- Tracks points across interaction segments using occlusion-robust techniques.
- Introduces a novel regularized twist estimation formulation to robustly infer revolute and prismatic joint parameters.
- Utilizes language models to classify the type of observed articulation motion (opening, closing, etc.).
3D Scene Graph Construction
- Maps objects and parts in a class-agnostic manner using incremental 3D reconstruction.
- Associates estimated articulation models with the corresponding object parts.
- Discovers objects contained within articulated containers by reasoning about their relative motion and occlusion.
Data & Experimental Setup
Arti4D-Semantic Dataset
- Extends the Arti4D dataset with semantic object labels, part-level articulation annotations, and parent-child containment relationships.
- Includes ego-centric, exo-centric, and robot-centric observation modalities across 62 sequences.
- Provides a benchmark for evaluating articulated scene understanding in unconstrained real-world settings.
Evaluation Tasks
- Temporal interaction segmentation
- Articulation parameter estimation (axis, type)
- 3D part segmentation and contained object discovery
- Real-world mobile manipulation on two robot platforms
Results
Interaction Segmentation
- MoMa-SG achieves the highest 1D-IoU, segment recall, and segment-based IoU compared to baselines.
Articulation Estimation
- MoMa-SG outperforms state-of-the-art methods on axis error, translation error, and articulation type accuracy.
- Ablations demonstrate the importance of the proposed twist regularization scheme.
3D Part Segmentation and Contained Objects
- MoMa-SG significantly outperforms baselines in segmenting articulated 3D parts and identifying contained objects.
- Achieves high open-vocabulary semantic retrieval accuracy for the articulated parts.
Real-World Mobile Manipulation
- Demonstrates robust articulation state estimation and manipulation on both a wheeled mobile manipulator (HSR) and a quadruped robot (Spot).
- Achieves over 80% success rate in opening and closing various articulated objects across environments.
Limitations
- Relies on accurate camera poses and real-world depth measurements, which may not always be available.
- Performance is limited by the quality of the underlying action recognition, which remains a challenging problem.
What Comes Next
- Explore techniques to reduce the reliance on accurate depth and camera pose information.
- Investigate semi-static rearrangements and their impact on the constructed scene graphs.
- Expand the dataset to include a wider variety of articulated objects and interaction modalities.