Story
Text Before Vision: Staged Knowledge Injection Matters for Agentic RLVR in Ultra-High-Resolution Remote Sensing Understanding
Key takeaway
A new AI system can better understand complex satellite images by first learning relevant information through text, before analyzing the visual data. This could improve how we use satellite imagery to study the environment and plan infrastructure.
Quick Explainer
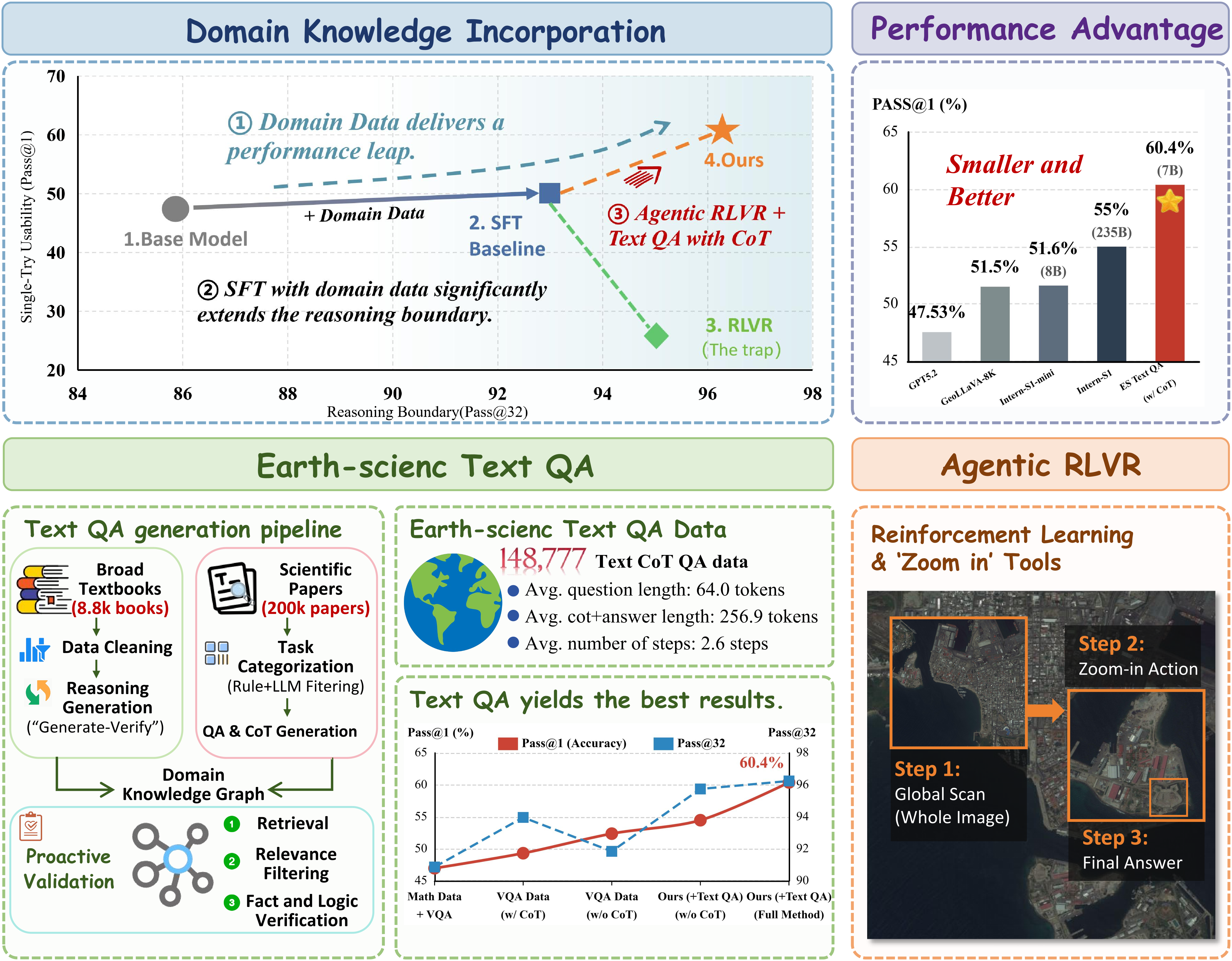
The authors propose a "Text-Before-Vision" training approach for agentic reinforcement learning with verifiable rewards (Agentic RLVR) to effectively leverage ultra-high-resolution remote sensing imagery. The key insight is that incorporating high-quality text-based domain knowledge, even without images, provides a stronger conceptual foundation for reasoning about the visual world compared to generic multimodal training alone. By first injecting this text-based prior knowledge during a supervised fine-tuning stage, and then using it to guide the subsequent Agentic RLVR exploration process, the authors achieve more stable and higher-performing results on the benchmark tasks, particularly in terms of reasoning boundary. This staged knowledge injection approach appears to be a crucial enabler for leveraging the full potential of ultra-high-resolution visual evidence.
Deep Dive
Technical Deep Dive: Text Before Vision: Staged Knowledge Injection Matters for Agentic RLVR in Ultra-High-Resolution Remote Sensing Understanding
Problem & Context
Ultra-high-resolution (UHR) remote sensing imagery provides unprecedented detail, but current machine learning models struggle to effectively acquire and leverage this visual evidence for reasoning tasks. While reinforcement learning with verifiable rewards (RLVR) and its agentic variant (Agentic RLVR) offer a path forward by enabling interactive visual exploration, the authors find that reasoning performance is primarily driven by the quality and modality of domain knowledge, rather than the post-training approach itself.
Methodology
The authors systematically compare three post-training paradigms - supervised fine-tuning (SFT), RLVR, and Agentic RLVR - on the XLRS-Bench benchmark for UHR remote sensing tasks. They analyze performance in terms of pass@1 (average success) and pass@32 (reasoning boundary). Key experiments include:
- Evaluating the impact of incorporating domain-specific data (SuperRS-VQA) versus general data (DeepEyes-47K)
- Assessing when to inject domain knowledge: during cold-start SFT vs. during the RL stage
- Comparing the effects of image-text data (SuperRS-VQA) versus text-only data (Earth Science QA)
Results
The authors make several key observations:
- Text-only data as a cold-start is more effective than image-text data: Incorporating high-quality Earth Science text-only QA during cold-start SFT improves both pass@1 and pass@32 more effectively than using image-text VQA data.
- Agentic RLVR delivers stable gains when combined with domain knowledge: While standard RLVR does not consistently outperform SFT, Agentic RLVR (with zoom-in tool) yields more stable improvements in average performance (pass@1) when domain knowledge is available.
- Reasoning boundary is primarily driven by domain prior coverage: Regardless of the post-training method, incorporating domain-specific data (text or image-text) consistently increases the pass@32 reasoning boundary.
- Earth Science text-only QA provides crucial domain priors: The authors find that high-quality text-only QA, with structured chain-of-thought reasoning, is a key driver of gains in both pass@1 and pass@32. This text-based domain knowledge appears to be more effective than image-text VQA data alone.
Interpretation
The authors attribute these findings to the unique challenges of UHR remote sensing, where effective visual evidence acquisition and alignment with domain concepts are crucial. Text-based domain knowledge, even without images, appears to provide stronger scaffolding for reasoning about the visual world compared to generic multimodal training alone.
Limitations & Uncertainties
- The authors note that their findings may be specific to the UHR remote sensing domain and may not generalize to other multimodal reasoning tasks.
- The relative importance of text-only versus image-text data may depend on factors like the complexity of the visual evidence and the maturity of the domain.
- It is unclear whether the benefits of text-based domain knowledge would extend to newer, more capable visual-language models.
What Comes Next
Building on these insights, the authors propose a "Text-Before-Vision" training recipe that leverages an automated pipeline for constructing large-scale, high-quality Earth Science text-only QA. This staged approach, combining text-based cold-start SFT with image-text "pre-warming" during Agentic RLVR, achieves state-of-the-art performance on the XLRS-Bench benchmark.