Story
TimeOmni-VL: Unified Models for Time Series Understanding and Generation
Key takeaway
Researchers developed a single AI model that can both generate new time series data and understand the meaning behind existing time series. This could lead to improved forecasting, monitoring, and analysis of real-world time-dependent phenomena.
Quick Explainer
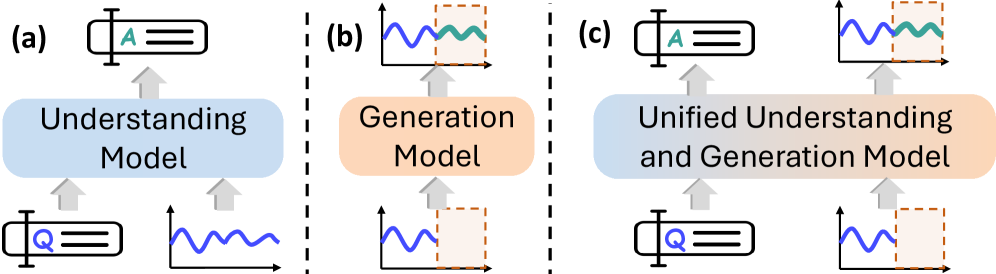
TimeOmni-VL is a unified framework that enables both understanding and generation of time series data by leveraging a vision-centric approach. The key idea is to establish robust bidirectional mappings between time series and their visual representations, preserving signal fidelity. This allows the model to internalize temporal understanding, which it then uses as a control signal to guide high-quality time series generation. The distinctive aspect of TimeOmni-VL is its ability to bridge the traditional divide between generation models focused on numerical precision and understanding models focused on temporal reasoning, achieving strong performance on both tasks within a single unified architecture.
Deep Dive
TimeOmni-VL: Unified Models for Time Series Understanding and Generation
Overview
This paper introduces TimeOmni-VL, the first vision-centric framework that unifies time series understanding and generation. Key contributions:
- Fidelity-preserving bidirectional Time Series ⇔ Image (Bi-TSI) mappings to prevent information loss during conversion.
- A generation pipeline that leverages temporal understanding as an explicit control signal for high-fidelity time series generation.
- A new benchmark comprising 6 understanding tasks and 2 generation tasks tailored to the TS-image representation.
- Comprehensive evaluation demonstrating TimeOmni-VL's strong performance on both understanding and generation.
Problem & Context
- Time series modeling faces a divide between generation models focused on numerical precision and understanding models focused on temporal reasoning.
- Existing approaches either lack explicit structural understanding (generation models) or struggle with numerical precision (understanding models).
- The vision community has seen advancements in unified multimodal models (UMMs) that excel at both understanding and generation, suggesting opportunities for time series.
Methodology
Fidelity-Preserving Bi-TSI
- Robust Fidelity Normalization (RFN) to stabilize dynamic-range projection and preserve signal geometry.
- Encoding Capacity Control to prevent implicit downsampling when rendering time series onto a fixed TS-image canvas.
Understanding-Guided Generation
- 6 understanding tasks (layout-level and signal-level) tailored to the TS-image representation.
- Generation pipeline follows a "understand-then-generate" paradigm, where the understanding model derives a generation-oriented Chain-of-Thought (CoT) to guide the generation module.
Data & Experimental Setup
- The TimeOmni dataset includes:
- 40,000 training samples each for forecasting and imputation generation tasks.
- 9,409 understanding task QA pairs.
- 2,339 temporal reasoning samples from TSR-Suite.
- Evaluation uses a representative subset of the GIFT-Eval benchmark.
- TimeOmni-VL is built on the Bagel-7B UMM backbone.
Results
Understanding Tasks
- Bagel-7B achieves near-perfect scores on 4 out of 6 understanding tasks after TimeOmni-VL post-training.
- Significant improvements from the base model, demonstrating that TimeOmni-VL internalizes temporal understanding.
Forecasting
- TimeOmni-VL establishes a new state-of-the-art, outperforming text-only and image-based time series models.
- The untuned Bagel-7B backbone fails without TimeOmni-VL's specialized training.
Imputation
- TimeOmni-VL reaches state-of-the-art imputation performance, leveraging both past and future contexts.
- Simple statistical baselines outperform text-only LLMs, highlighting the importance of numerical precision.
Reasoning
- TimeOmni-VL achieves top-2 performance on 3 out of 4 text-based temporal reasoning tasks.
- Demonstrates effective injection of time series domain knowledge into the UMM.
Interpretation
- TimeOmni-VL bridges the understanding-generation divide by internalizing both capabilities within a unified framework.
- The vision-centric approach, with fidelity-preserving Bi-TSI and understanding-guided generation, enables TimeOmni-VL to outperform specialized time series models.
- Temporal understanding serves as a crucial control signal, boosting generation quality by an average of 8.2%.
Limitations & Uncertainties
- The current dataset and evaluation are limited to specific generation tasks and a representative subset of the GIFT-Eval benchmark.
- Further scaling and diversification of the dataset could unlock TimeOmni-VL's full potential.
- The efficacy of the understanding-guided generation mechanism may depend on the specific task and dataset characteristics.
What Comes Next
- Explore TimeOmni-VL's generalization to a broader range of time series tasks and datasets.
- Investigate the transferability of temporal understanding to other vision-language applications.
- Extend the vision-centric approach to handle multimodal time series data beyond just numeric signals.