Story
Prompt When the Animal is: Temporal Animal Behavior Grounding with Positional Recovery Training
Key takeaway
Researchers developed a new technique to better track and understand animal behavior by recovering their positions over time, which could improve wildlife monitoring and conservation efforts.
Quick Explainer
The key idea of Prompt When the Animal is (PWTA) is to guide the model's attention to the relevant temporal regions when localizing animal behaviors in video, overcoming the challenge of sparse, uniformly distributed moments in animal behavior data. PWTA achieves this through Positional Recovery Training (PRT), which prompts the model with the true start and end times of target behaviors during training. This helps the model align its predictions with the ground-truth temporal positions, in contrast to relying solely on the sparse cues in the data. The novel Dual-alignment component further reinforces this alignment, making PWTA an effective approach for temporal grounding of animal behavior.
Deep Dive
Technical Deep Dive: Temporal Animal Behavior Grounding with Positional Recovery Training
Overview
This work proposes a novel framework called "Prompt When the Animal is" (PWTA) for the task of temporal animal behavior grounding. Temporal grounding involves localizing moments in video that correspond to given language queries. The authors identify key challenges when applying this task to animal behavior data, specifically the sparsity and uniform distribution of meaningful moments compared to conventional benchmarks.
To address these challenges, PWTA introduces a Positional Recovery Training (PRT) approach that prompts the model with the start and end times of target animal behaviors during training. This helps the model focus on the relevant temporal regions, overcoming the lack of strong positional biases in animal behavior data. Experiments on the Animal Kingdom dataset demonstrate the effectiveness of PWTA, with it emerging as a top performer in the MMVRAC 2024 competition.
Problem & Context
- Temporal grounding is crucial for multimodal learning, but poses challenges when applied to animal behavior data
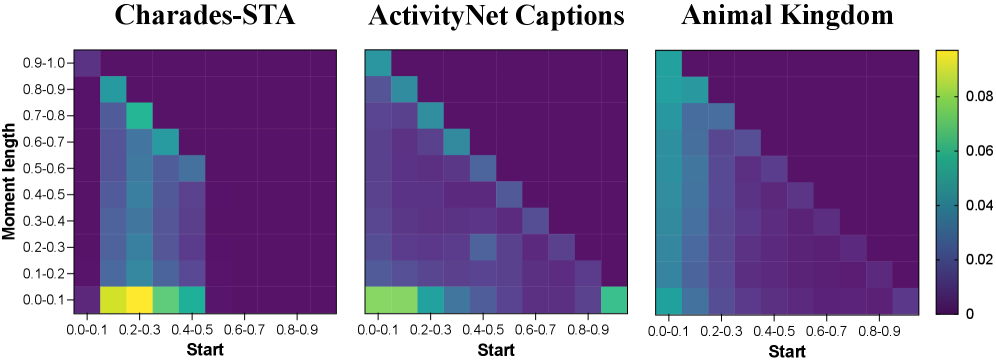
- Animal behavior data exhibits sparse, uniformly distributed moments compared to conventional benchmarks
- Animal Kingdom dataset has an average normalized moment length of only 0.19, vs 0.27-0.32 for other datasets
- Temporal position distribution is more uniform, lacking the strong positional biases seen in other datasets
- Existing methods like VSLNet and LGI perform well on conventional benchmarks but struggle on animal behavior data due to these discrepancies
Methodology
PWTA builds upon the VSLNet architecture, with a focus on enhancing the span predictor:
- Predicting Branch: Performs standard boundary regression to predict start and end timestamps
- Recovering Branch: Receives corrupted (flipped) start/end label embeddings and learns to reconstruct the original positions
- Dual-alignment: Forces the Predicting Branch distributions to align with the more accurate Recovering Branch distributions, prompting the model to focus on relevant temporal regions
This Positional Recovery Training (PRT) approach leverages the ground-truth start/end times as a form of prompting, helping the model overcome the lack of positional biases in animal behavior data.
Data & Experimental Setup
- Animal Kingdom dataset: 50 hours of video, 18,744 annotated sentences, 8:2 train/test split
- Evaluation metrics: IoU@0.3, IoU@0.5, IoU@0.7, and mean IoU (mIoU)
- Implementation details:
- AdamW optimizer, batch size 16, initial learning rate 2e-4
- Maximum video length 128, model hidden dimension 256
- Flip rate for PRT set to 0.2, loss balancing parameters λrec and λalign both set to 1.0
Results
- PWTA outperforms previous state-of-the-art methods like VSLNet and LGI on the Animal Kingdom dataset
- Achieves IoU@0.3 of 38.52, compared to 33.74 for VSLNet and 33.51 for LGI
- Significantly improves mIoU from 25.02 (VSLNet) to 28.10
- Ablation study confirms the importance of the Dual-alignment component for effective Positional Recovery Training
Interpretation
- The Positional Recovery Training approach successfully prompts the model to focus on relevant temporal regions, overcoming the lack of strong positional biases in animal behavior data
- Aligning the Predicting Branch distributions with the more accurate Recovering Branch distributions is crucial for this approach to work effectively
- PWTA demonstrates the value of leveraging ground-truth information (start/end times) to guide the model, rather than relying solely on learning from the data
Limitations & Uncertainties
- PWTA's performance starts to degrade for very long videos (>30s), likely due to compressing them to a fixed length of 128 frames
- The authors note that even small variations in the localized span indices can result in significant changes in the corresponding times after transformation, making the method unstable for long videos
What Comes Next
- Future work may consider leveraging language models to identify the subject animals of the moments, and adding a classification branch to enhance model robustness
- Exploring ways to better handle long video sequences, such as variable-length modeling or more sophisticated temporal reasoning, could further improve PWTA's performance