Story
Beyond Needle(s) in the Embodied Haystack: Environment, Architecture, and Training Considerations for Long Context Reasoning
Key takeaway
Researchers developed a new framework called $\infty$-THOR that can better understand and reason about long-term contexts in embodied AI systems, which could lead to more capable and contextually-aware AI assistants.
Quick Explainer
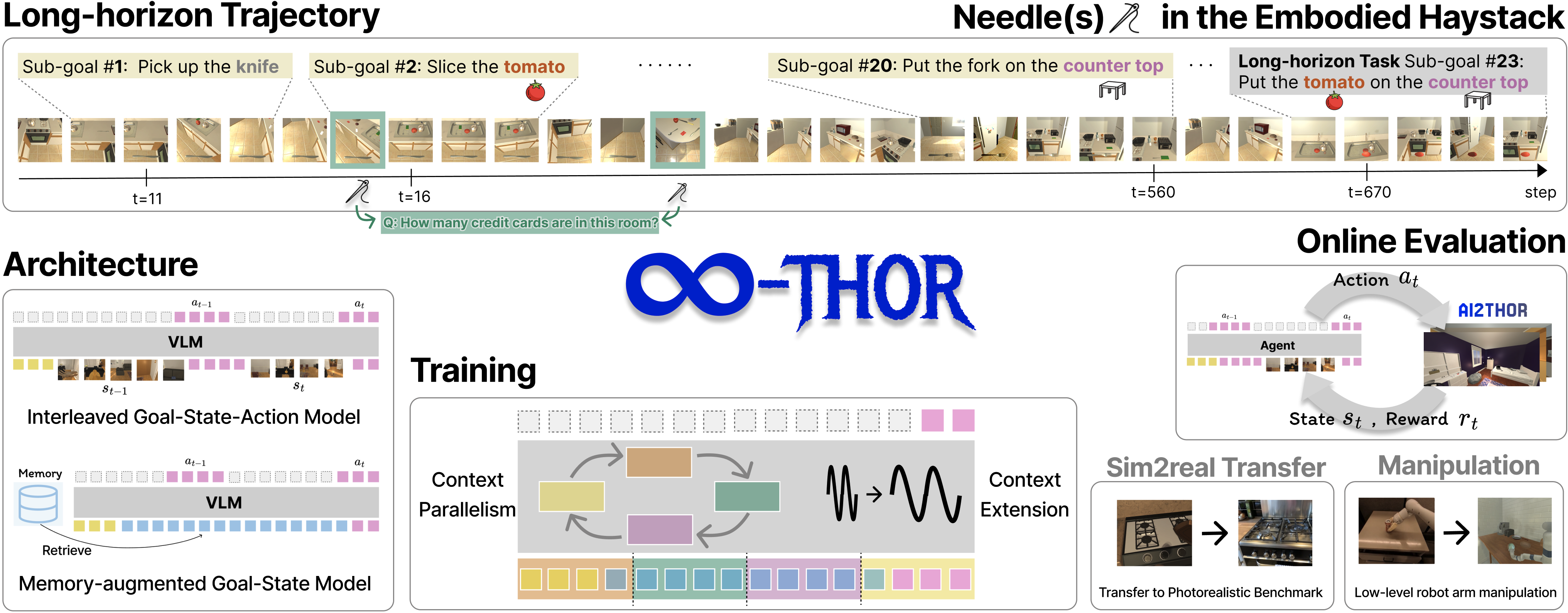
The core idea is to train embodied AI agents capable of long-horizon reasoning across complex, synthetic trajectories in the AI2-THOR environment. The key is a generation framework that produces scalable, reproducible, and unlimited long-horizon trajectories, along with a benchmark called "Needle(s) in the Embodied Haystack" that tests agents' ability to recall and reason over scattered clues. The authors explore architectural choices like Interleaved Goal-State-Action and Memory-Augmented models, as well as training strategies like Context Extension and Parallelism, to handle the extreme context lengths required for this task. This work highlights the significant challenges current state-of-the-art vision-language models face in long-term reasoning and planning, and points towards future research directions for robust embodied AI.
Deep Dive
Technical Deep Dive: Beyond Needle(s) in the Embodied Haystack
Overview
This paper introduces a new framework for training and evaluating long-horizon embodied AI agents. The key contributions are:
- A generation framework for synthesizing scalable, reproducible, and unlimited long-horizon trajectories in the AI2-THOR environment.
- A novel embodied QA benchmark, "Needle(s) in the Embodied Haystack" (NiEH), which tests agents' ability to recall and reason over scattered clues across extended trajectories.
- A large-scale dataset of long-horizon trajectories paired with ground-truth action sequences, supporting both offline imitation learning and online policy execution.
- Architectural explorations, including Interleaved Goal-State-Action and Memory-Augmented models, as well as training strategies like Context Extension and Context Parallelism to handle extreme context lengths.
- Experiments demonstrating the challenges of long-horizon reasoning, successful Sim2Real transfer, and integration with low-level manipulation controls.
Methodology
Environment and Benchmark
- The authors built upon the AI2-THOR environment to generate long, complex trajectories with synthetic final goals requiring multi-step reasoning across hundreds of steps.
- The "Needle(s) in the Embodied Haystack" (NiEH) benchmark poses two main challenges: (1) recalling multiple scattered clues, and (2) reasoning over multimodal (visual and linguistic) observations.
- NiEH features diverse question types, including binary, "what", "where", and "how many" questions, with varying difficulty levels.
Architectural Approaches
- Interleaved Goal-State-Action Model: Encodes the full perception-action history as a single multimodal sequence.
- Memory-Augmented Goal-State Model: Incorporates compact textual or visual summaries of past states to provide long-term context.
- Context Extension Techniques: Methods like Linear Interpolation, Dynamic Scaling, YaRN, and LongRoPE to handle input sequences beyond model pretraining limits.
- Context Parallelism: Enables efficient fine-tuning and inference on ultra-long sequences.
Dataset Construction
- Trajectory Replay and Metadata Collection: Logged egocentric views and scene metadata (objects, containers, interactions) during trajectory replay.
- Rule-Based QA Generation: Applied templates to the replay logs to synthesize diverse question types about object presence, state, location, actions, and counting.
- Cross-Validation with Multimodal LLMs: Filtered out questions that none of four powerful multimodal models (LLaVA-OV, Qwen2.5-VL, Deepseek-VL, Pixtral) could answer correctly.
Results
Static Evaluation: Needle(s) in the Embodied Haystack
- LLaVA-OV struggled to process full trajectories (>1M tokens), while Gemini 2.0 Flash performed robustly up to 256K tokens.
- Memory-Augmented approaches with textual summaries outperformed image-based memory retrieval.
- Multi-evidence questions were significantly more challenging than single-evidence, especially for sparse or temporally distant clues.
Online Evaluation: Long-Horizon Tasks
- LLaVA-OV failed to complete any long-horizon tasks, while Qwen2.5-VL achieved a maximum 11.5% success rate.
- Interleaved models outperformed Memory-Augmented approaches, and access to longer contexts (128K vs. 32K) during training led to substantial gains.
- Incorporating YaRN (x4) context extension provided an additional 2.3% boost in success rate.
Sim2Real Transfer and Low-Level Manipulation
- Fine-tuning on the NiEH QA dataset improved Qwen2.5-VL's performance on the photorealistic VSI-Bench by +11.2% on the Object Appearance Order task.
- Integration with ManipulaTHOR for low-level robot arm control showed that existing VLA models (OpenVLA-7B, SpatialVLA-4B) struggled, primarily due to differences in camera perspectives and robot arm configurations.
Interpretation
- The authors' long-horizon environment and NiEH benchmark pose significant challenges for current state-of-the-art VLMs, especially in reasoning over sparse, temporally distant evidence.
- Architectural choices like Interleaved Goal-State-Action modeling and access to longer context during training are critical for improving long-horizon performance.
- While context extension techniques and parallelism provide gains, the task remains unsolved, highlighting the need for further research into robust long-term reasoning and planning capabilities in embodied AI.
- The successful Sim2Real transfer demonstrates the potential for synthetic datasets to improve real-world performance, while the low-level manipulation results underline the importance of domain alignment and diverse training data.
Limitations & Uncertainties
- The long-horizon trajectories are synthesized within the constrained AI2-THOR environment, which may limit diversity and introduce biases compared to unstructured real-world scenarios.
- The NiEH benchmark focuses on reasoning over visual and linguistic observations, but real-world embodied tasks may involve additional modalities (e.g., audio, haptic feedback) that were not considered.
- The low-level manipulation experiments were conducted in simulation, and performance may differ when deploying to physical robot platforms due to factors like sensor noise, actuation uncertainties, and environmental differences.
What Comes Next
- Exploring methods to further scale context lengths and enhance long-term memory in VLM-based agents, potentially through more sophisticated memory architectures or neuro-symbolic reasoning.
- Expanding the diversity of environments, tasks, and modalities to better reflect the complexity of real-world embodied reasoning.
- Developing techniques to bridge the gap between simulation and the physical world, enabling robust sim-to-real transfer for low-level control and manipulation.
- Investigating meta-learning or few-shot adaptation approaches to equip embodied agents with the flexibility to handle novel tasks and environments.