Story
HiVAE: Hierarchical Latent Variables for Scalable Theory of Mind
Key takeaway
Researchers developed an AI system called HiVAE that can better understand people's thoughts and goals, a capability that could improve AI's ability to interact naturally with humans.
Quick Explainer
HiVAE takes inspiration from the belief-desire-intention (BDI) structure of human cognition, using a hierarchical variational architecture to reason about an agent's mental states and predict their goals. By fusing temporal movement patterns and spatial graph structure through parallel encoding pathways, HiVAE constructs a three-level hierarchical latent representation capturing beliefs, desires, and intentions. This hierarchical VAE model outperforms baselines on a large-scale campus navigation task, demonstrating improved robustness to misleading cues and preference changes. The authors note that the learned latent representations still lack explicit grounding to actual mental states, proposing self-supervised alignment strategies as future work.
Deep Dive
Technical Deep Dive: HiVAE for Scalable Theory of Mind
Overview
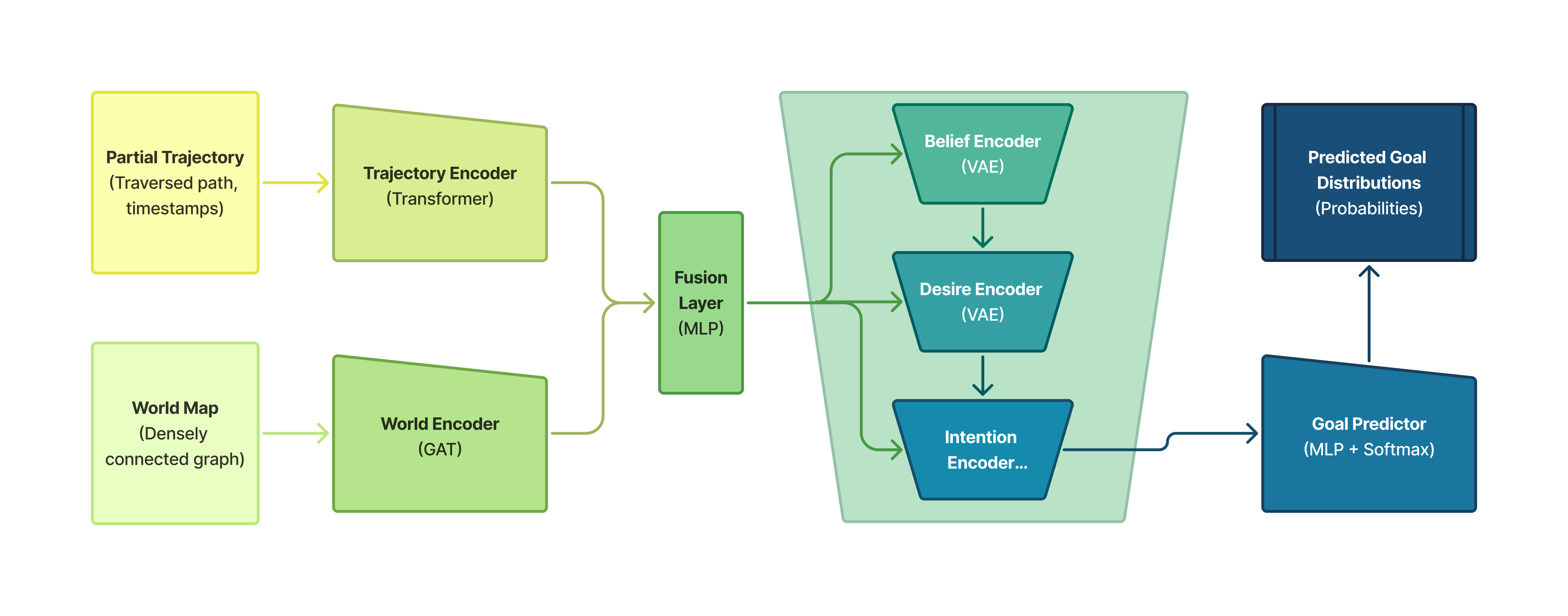
HiVAE is a hierarchical variational architecture that aims to scale theory of mind (ToM) reasoning to realistic spatiotemporal domains, going beyond previous work focused on small, human-understandable gridworlds. Inspired by the belief-desire-intention (BDI) structure of human cognition, HiVAE's three-level VAE hierarchy achieves substantial performance improvements on a 3,185-node campus navigation task.
Methodology
HiVAE's architecture consists of three main components:
- Trajectory-Graph Encoder: Processes both temporal movement patterns and spatial graph structure through parallel encoding pathways using Transformers and Graph Attention Networks.
- Hierarchical Mind-State VAE: Constructs a three-level hierarchical VAE, where each level (beliefs, desires, intentions) learns a latent variable conditioned on the fused encoding and previous mental states.
- Goal Prediction: Maps the concatenated mental state latents to a probability distribution over all possible goals.
The model is trained to minimize a composite objective of goal prediction loss, KL regularization, and reconstruction losses for the hierarchical VAE.
Data & Experimental Setup
The authors evaluate HiVAE on a synthetic pedestrian dataset over a real-world campus graph with 3,185 nodes and 9,000 edges. The dataset consists of 100,000 trajectories from 100 agents with individualized goal preferences, split 70/30 for training and testing.
Results
HiVAE consistently achieves the lowest Brier scores for goal prediction across all path observation fractions, outperforming baselines like Extended BToM, GRU, LSTM, and ToMNet by a large margin. Statistical tests confirm the significance of these performance improvements.
The authors also find that HiVAE is more robust than other models in the presence of misleading "false goals" near the agent's true destination. Additionally, HiVAE demonstrates greater stability under non-stationary changes to agent preferences, maintaining performance while other models suffer significant drops.
Limitations & Uncertainties
The authors identify a key limitation in that the learned latent representations in HiVAE lack explicit grounding to actual mental states. To address this, they propose several self-supervised alignment strategies, such as contrastive learning for desire embeddings, auxiliary prediction for beliefs, and intention consistency.
Other future work includes incorporating meta-learned agent embeddings for personalization, exploring alternative latent architectures beyond hierarchical VAEs, and bridging the theoretical ToM model to real-world trajectory data from domains like healthcare monitoring.