Story
Position-Aware Scene-Appearance Disentanglement for Bidirectional Photoacoustic Microscopy Registration
Key takeaway
Researchers developed a technique to align microscope images taken from opposite scan directions, which could improve the speed and accuracy of photoacoustic imaging used for medical diagnosis and research.
Quick Explainer
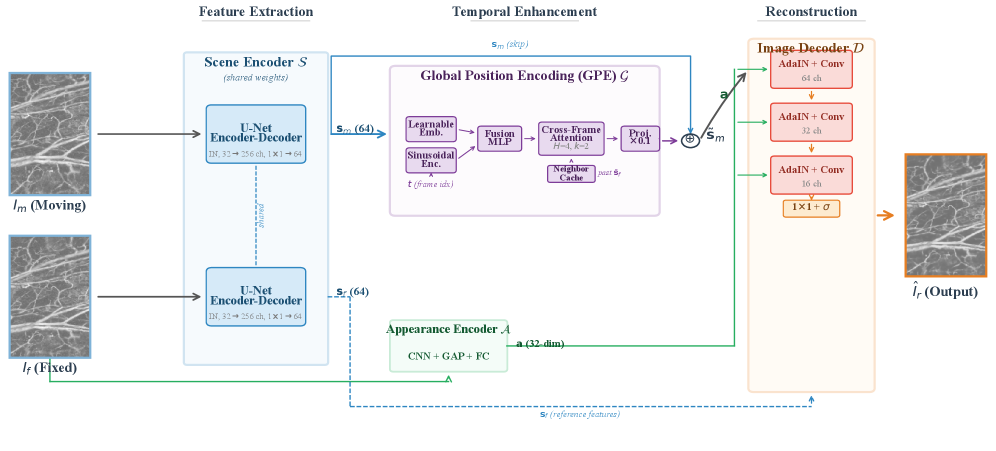
The paper presents a deep learning framework called GPEReg-Net that addresses a key challenge in bidirectional photoacoustic microscopy (OR-PAM) imaging - the systematic geometric and intensity misalignment between forward and backward scan lines. GPEReg-Net tackles this by disentangling each input image into a domain-invariant scene representation and a global appearance code, then using adaptive instance normalization to modulate the scene features with the target appearance. Crucially, it also enhances the scene features with temporal context from neighboring frames via a Global Position Encoding module, enabling direct image-to-image registration without explicit deformation field estimation. This novel approach allows GPEReg-Net to achieve high-quality alignment on the OR-PAM-Reg-4K benchmark.
Deep Dive
Technical Deep Dive: Position-Aware Scene-Appearance Disentanglement for Bidirectional Photoacoustic Microscopy Registration
Overview
The paper proposes GPEReg-Net, a deep learning framework for aligning bidirectional photoacoustic microscopy (OR-PAM) images. Bidirectional scanning in OR-PAM introduces systematic geometric and intensity misalignment between forward and backward scan lines, violating assumptions of classical registration methods. GPEReg-Net addresses this by:
- Disentangling each input image into a domain-invariant scene representation and a global appearance code, then using Adaptive Instance Normalization (AdaIN) to modulate the scene features with the target appearance.
- Enhancing the scene features with temporal context from neighboring frames via a Global Position Encoding (GPE) module that combines learnable position embeddings and sinusoidal encoding with cross-frame attention.
This approach enables direct image-to-image registration without explicit deformation field estimation, achieving high-quality alignment on the OR-PAM-Reg-4K benchmark.
Problem & Context
- OR-PAM combines optical imaging resolution with photoacoustic sensitivity, enabling label-free visualization of cellular-level structures.
- Bidirectional raster scanning in high-speed OR-PAM systems introduces coupled domain shift and geometric misalignment between forward and backward scan lines.
- Existing registration methods, constrained by brightness constancy assumptions, achieve limited accuracy due to the intensity differences between forward and backward acquisitions.
Methodology
- The framework consists of four modules:
- SceneEncoder $S$: Extracts domain-invariant scene features $s$ using Instance Normalization.
- AppearanceEncoder $A$: Extracts a 32-dimensional global appearance code $a$ that captures the intensity profile.
- Global Position Encoding $G$: Enhances scene features $s$ with temporal context from neighboring frames.
- ImageDecoder $D$: Reconstructs the registered output $\hat{I_r}$ by modulating $s$ with $a$ using AdaIN.
- The training objective combines reconstruction loss and a scene alignment regularizer to encourage domain-invariant representations.
Data & Experimental Setup
- Evaluated on two OR-PAM benchmarks:
- OR-PAM-Reg-4K: 4,248 image pairs, split into 3,396 training, 420 validation, 432 test.
- OR-PAM-Reg-Temporal-26K: 26,000+ temporally ordered pairs.
- Metrics: NCC, SSIM, PSNR between registered even columns and fixed odd columns.
- Additional temporal metrics: TNCC/TSSIM (inter-frame coherence), TNCG/TSSG (deviation from reference).
Results
- On OR-PAM-Reg-4K, GPEReg-Net achieves:
- NCC: 0.953, SSIM: 0.932 (+3.8% over prior SOTA), PSNR: 34.49 dB (+1.99 dB over prior SOTA).
- Outperforms classical and deformation-based deep learning methods.
- On OR-PAM-Reg-Temporal-26K:
- Intra-frame quality degrades (NCC: 0.921, SSIM: 0.634, PSNR: 27.22 dB).
- But maintains strong temporal coherence with TNCC: 0.969 and TSSIM: 0.944, exceeding the reference ceiling.
Interpretation
- Scene-appearance disentanglement is well-suited for the global domain shift in bidirectional OR-PAM, where the appearance code can capture the systematic intensity difference.
- The GPE module's temporal awareness improves registration consistency across frames, exceeding the natural inter-frame dynamics.
- Limitations under high temporal variability (OR-PAM-Reg-Temporal-26K) suggest the need for:
- Adaptive position encoding that can generalize to variable-length sequences.
- Spatially-aware appearance modeling to handle heterogeneous domain shifts.
Limitations & Uncertainties
- Ground-truth registered images are unavailable for bidirectional OR-PAM data, so evaluation uses a reference-free strategy.
- The global scene-appearance disentanglement assumption partially breaks down under extended temporal variability.
- The fixed-capacity learnable position embedding table in the GPE module cannot adequately represent diverse temporal patterns in long-term acquisitions.
What Comes Next
Future work should explore:
- Adaptive position encoding mechanisms that can generalize to variable-length sequences.
- Spatially-aware appearance modeling to capture locally varying domain shifts for improved robustness in longitudinal imaging studies.
Sources: