Story
AllMem: A Memory-centric Recipe for Efficient Long-context Modeling
Key takeaway
Researchers developed a new memory-efficient algorithm that improves the performance of large language models on long text tasks, potentially making these advanced AI systems more practical for real-world applications.
Quick Explainer
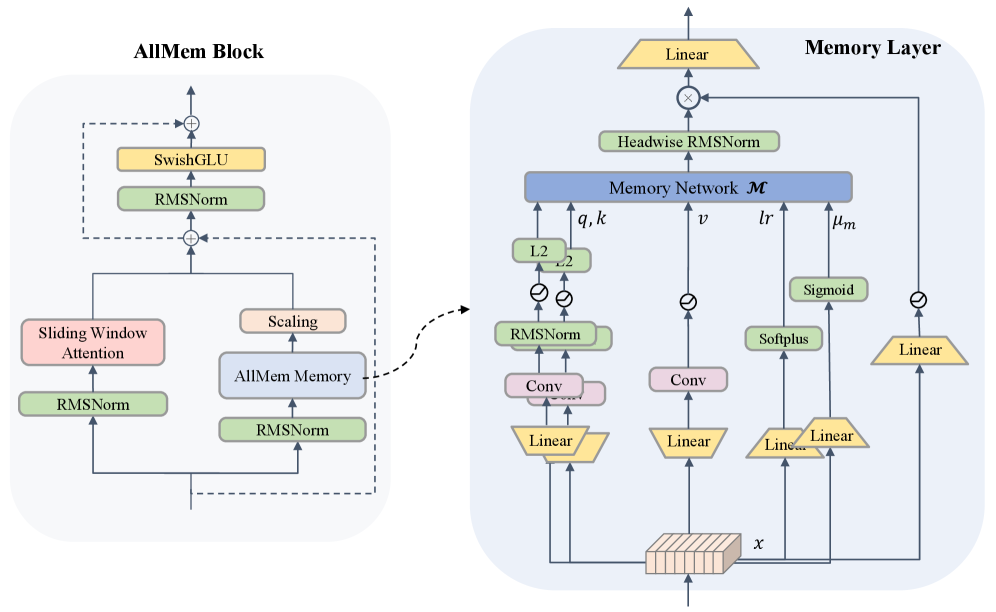
The AllMem architecture addresses the performance challenges of large language models processing long sequences. It combines a sliding window attention mechanism with an active, learning memory module that can dynamically compress and retrieve information across multiple timescales. This allows the model to efficiently model long-context dependencies by separating short-term adaptation from the persistence of stable, abstract knowledge in long-term memory. The key innovation is treating the memory as an adaptive learning system, rather than just a passive storage component, enabling it to continuously optimize its internal representations during inference.
Deep Dive
Technical Deep Dive: AllMem - A Memory-centric Recipe for Efficient Long-context Modeling
Problem & Context
Large Language Models (LLMs) face significant performance bottlenecks when processing long sequences due to the computational complexity and memory overhead inherent in the self-attention mechanism. The O(L^2) computational complexity and O(L) memory access overhead of Softmax attention make it infeasible to effectively model sequences exceeding the pre-trained context window, especially on edge devices with limited resources.
Methodology
To address these challenges, the authors propose a novel architecture called AllMem that integrates Sliding Window Attention (SWA) with non-linear Test-Time Training (TTT) memory networks. The key innovations are:
- Memory as a Learning System: The memory module functions as an active, hierarchical learning system capable of abstracting, compressing, and retrieving knowledge, rather than just passively storing information.
- Learning Across Multiscale Temporal Dynamics: The memory learning is inherently multiscale, with long-term learning establishing stable reasoning patterns and persistent knowledge, while short-term learning enables rapid, context-sensitive adaptation.
The AllMem model uses a parallel, modular architecture that decouples long-term persistent memory from precise short-term memory. These two modalities are dynamically fused via a learnable, channel-wise scaling gate mechanism.
The TTT-enabled memory network is optimized online during inference using a momentum-based stochastic gradient descent (SGD) optimizer with input-dependent dynamic learning rates and momentum coefficients. This allows the model to continuously update and compress the long-term memory state.
Data & Experimental Setup
The authors use the Qwen3 series models as the foundational architecture and evaluate on a diverse set of benchmarks:
- Short-sequence tasks: C-Eval, ARC, HellaSwag, WinoGrande, MMLU-Redux, GPQA-Diamond, MATH-500, LiveCodeBench
- Long-context tasks: LongBench, InfiniteBench, LV-Eval
They also compare AllMem against baselines like full attention, sliding-window attention with "sink" tokens, and a Mamba-enhanced memory model.
Results
- On short-sequence benchmarks, the AllMem models achieve performance comparable to or exceeding the original Qwen3 models.
- On long-context benchmarks:
- On LongBench (avg. seq. length 37k), the 4k-window AllMem model matches the performance of full attention.
- On InfiniteBench and LV-Eval (128k context), the 8k-window AllMem-1.7B model outperforms full attention.
- The AllMem architecture provides significant computational and memory efficiency gains:
- At 128k context length, the AllMem model uses only 11% of the computational cost and memory overhead of the full attention model.
Interpretation
The results demonstrate that the AllMem architecture can effectively compress long-sequence information by leveraging the test-time learning memory module, while retaining strong performance on short-sequence tasks. The modular design with dynamic fusion of short-term and long-term memory enables efficient and adaptive long-context modeling.
Limitations & Uncertainties
- The generation hyperparameters used in the experiments were not specifically optimized for the AllMem model, suggesting potential for further performance improvements.
- The authors only evaluate on a limited set of benchmarks and do not provide analysis of the model's qualitative behaviors or robustness.
- The training and fine-tuning process is complex, and the impact of individual components (e.g., normalization, gating) is not isolated.
What Comes Next
- Explore integration of the AllMem memory mechanism with external persistent memory systems (e.g., RAG, Engram) to construct a multi-level memory hierarchy.
- Investigate the qualitative behaviors and robustness of the AllMem model through in-depth analysis and case studies.
- Simplify the training and fine-tuning process while retaining the performance benefits of the AllMem architecture.
Sources: