Story
CLEF HIPE-2026: Evaluating Accurate and Efficient Person-Place Relation Extraction from Multilingual Historical Texts
Key takeaway
A new CLEF evaluation lab will test how well AI systems can extract information about people and places from old texts written in different languages. This could help historians and journalists better understand the connections between historical figures and locations.
Quick Explainer
The CLEF HIPE-2026 task focuses on automatically extracting semantic relations between people and places from multilingual historical texts. The key idea is to classify each person-place pair as either "true" (explicit evidence), "probable" (implied but not stated), or "false" (no evidence) based on the text. This requires understanding temporal context and geographic inferences to determine whether a person was present at a location around the time of the document's publication. The task is designed to be approachable by both language models and traditional classification approaches, with a focus on scalable and efficient methods to handle the growing volume of historical data. The goal is to enable reconstructing individuals' geographical and temporal trajectories to support digital humanities research.
Deep Dive
Technical Deep Dive: CLEF HIPE-2026 - Evaluating Accurate and Efficient Person-Place Relation Extraction
Problem Statement
HIPE-2026 is a CLEF evaluation lab focused on extracting semantic person-place relations from multilingual historical texts. The goal is to automatically detect where a person was located at the time of a document's publication, or anytime prior, based on evidence in the text. This enables reconstructing individuals' geographical and temporal trajectories to support digital humanities research.
Methodology
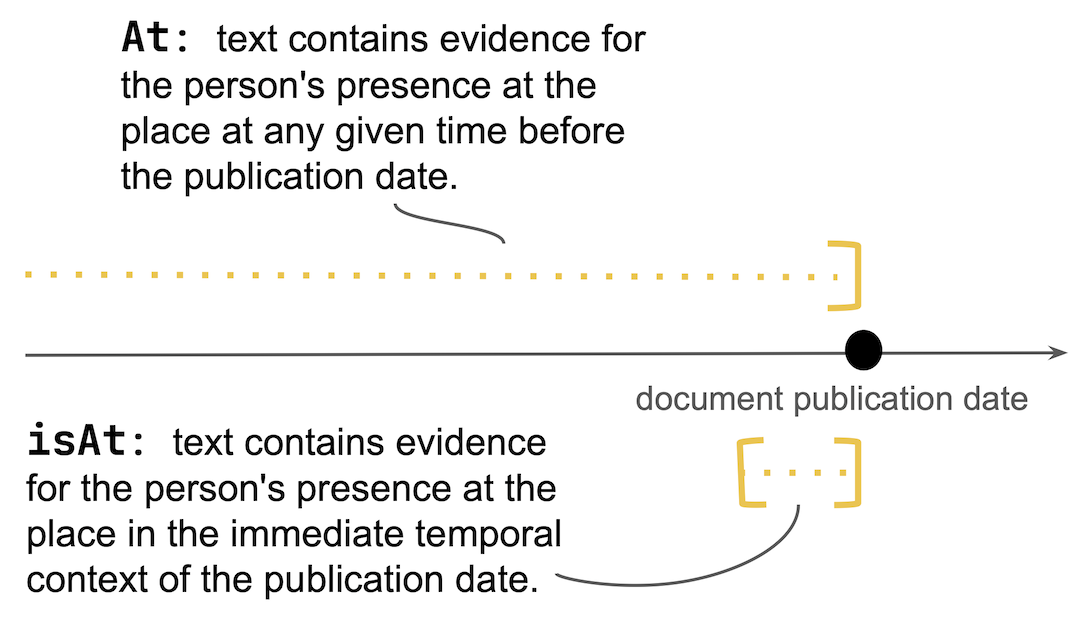
The task is formulated as a relation classification problem, where systems must label each person-place pair in a document with one of three possible "at" relations:
- True: The text provides explicit evidence that the person was present at the place.
- Probable: The text implies the person was likely present at the place, but does not state it explicitly.
- False: There is no evidence, or contradictory evidence, that the person was at the place.
Additionally, systems must predict a binary "isAt" label indicating whether the person was present at the location around the document's publication time.
This requires temporal reasoning, geographic inference, and interpretation of noisy historical texts with sparse contextual cues. The task is designed to be approachable by both generative language models and more traditional classification approaches.
Data & Experimental Setup
The HIPE-2026 dataset consists of two test sets:
- Test Set A: Historical newspaper articles in French, German, English, and Luxembourgish spanning the 19th-20th centuries.
- Surprise Test Set B: French literary texts from the 16th-18th centuries, used to evaluate domain generalization.
A pilot study on the HIPE-2022 development data found:
- Inter-annotator agreement (Cohen's kappa) ranged from 0.7-0.9 for "at" and 0.4-0.9 for "isAt", indicating moderate to high consistency.
- GPT-4 achieved up to 0.8 agreement with the gold standard for "at", but lower and more variable results for "isAt" (0.2-0.7).
- The high inference cost and quadratic scaling of candidate entity pairs in historical documents highlight the need for scalable, efficient methods.
Evaluation
HIPE-2026 uses three evaluation profiles:
- Accuracy Profile: Macro-averaged Recall, which ensures all relation labels contribute equally regardless of class imbalance.
- Accuracy-Efficiency Profile: Balances predictive performance with model efficiency and resource usage.
- Generalization Profile: Evaluates "at" relation accuracy on the Surprise Test Set B.
The dataset, baselines, and scoring tools are publicly released to promote reproducibility and further research.
Limitations & Uncertainties
- The task requires complex temporal and geographic reasoning over noisy, historical text, which remains challenging for current models.
- The dataset size may limit the ability to thoroughly evaluate domain generalization, particularly for low-resource languages and time periods.
- The "probable" label introduces subjectivity, as it depends on abductive inferences that can vary across annotators and models.
What Comes Next
HIPE-2026 aims to advance the state of the art in relation extraction for historical and multilingual domains. The results will inform future work on:
- Robust methods for mining person-place relations from digitized historical materials.
- Techniques for efficient, scalable relation extraction to handle the growing volume of historical data.
- Approaches for cross-lingual transfer and domain adaptation to improve generalization.
- Leveraging relation extraction to support downstream applications in digital humanities, such as biography reconstruction and spatial analysis.