Story
MALLVI: a multi agent framework for integrated generalized robotics manipulation
Key takeaway
Researchers developed a new AI framework that allows robots to plan and carry out complex manipulation tasks, paving the way for more versatile and capable robots that can assist humans in a variety of settings.
Quick Explainer
MALLVI is a novel framework for robotic manipulation that combines large language models and vision-language models to plan and execute tasks in a closed-loop, feedback-driven manner. The key idea is a distributed, modular architecture with specialized agents for perception, planning, and error recovery. This allows MALLVI to break down high-level instructions, build a dynamic spatial representation of the environment, and adapt its actions based on continuous visual feedback. The distinctive aspect is the Reflector agent, which monitors execution and selectively triggers targeted error recovery, avoiding costly global replanning. This multi-agent coordination and closed-loop feedback mechanism enables MALLVI to effectively disambiguate instructions, adapt to dynamic environments, and recover from failures.
Deep Dive
Technical Deep Dive: MALLVI - A Multi-Agent Framework for Integrated Generalized Robotics Manipulation
Overview
MALLVI is a multi-agent framework that combines large language models (LLMs) and vision-language models (VLMs) to plan and execute robotic manipulation tasks in a closed-loop, feedback-driven manner. The key innovations are:
- A distributed, modular architecture with specialized agents for perception, planning, and reflection
- A reflector agent that continuously monitors execution and triggers targeted error recovery
- Integration of open-vocabulary object detection, segmentation, and grounding for precise manipulation
Problem & Context
- Previous approaches to robotic task planning using LLMs have been fragile, operating in an open-loop manner without environmental feedback
- Existing systems often lack task-aware decomposition, flexible perception-action pipelines, and the ability to adapt to dynamic environments
Methodology
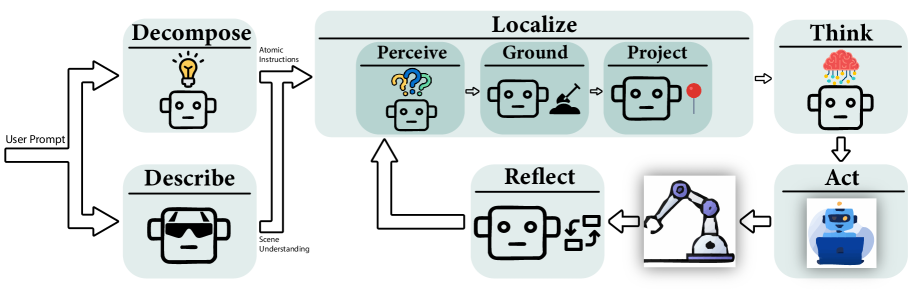
Multi-Agent Architecture
- MALLVI coordinates multiple LLM and VLM agents, each responsible for a distinct component of the manipulation pipeline:
- Decomposer: Breaks high-level instructions into atomic subtasks
- Descriptor: Generates a spatial graph representation of the environment
- Localizer: Detects and localizes objects using multi-model fusion
- Thinker: Translates subtasks into executable parameters
- Actor: Executes subtasks in the environment
- Reflector: Monitors execution using visual feedback and triggers error recovery
- The modular design allows specialized agents to collaborate through a shared memory state
Closed-Loop Feedback and Error Recovery
- The Reflector agent continuously evaluates the success of each subtask execution using visual feedback
- Upon detecting failure, it selectively reactivates the relevant agent to reattempt the subtask, avoiding costly global replanning
- The Descriptor agent performs complete scene re-analysis when necessary to update the shared visual memory
Data & Experimental Setup
- Evaluated on real-world manipulation tasks as well as benchmarks from VIMABench and RLBench
- Real-world tasks include object placement, sorting, stacking, and sequential reasoning
- VIMABench tasks test spatial reasoning, attribute binding, and goal-directed planning
- RLBench provides a large-scale benchmark for instruction-conditioned control
Results
- MALLVI outperformed prior state-of-the-art methods across all evaluated tasks
- Ablation studies demonstrated the critical importance of the reflector agent and multi-agent coordination
- MALLVI achieved the highest success rates, highlighting its robust generalization to diverse manipulation scenarios
Interpretation
- The multi-agent architecture and closed-loop feedback mechanism enable MALLVI to disambiguate instructions, adapt to dynamic environments, and recover from errors
- Specialized agents for perception, reasoning, and execution allow MALLVI to maintain task focus and perform sequential reasoning more effectively than monolithic systems
Limitations & Uncertainties
- MALLVI still relies on predefined atomic actions for execution, constraining adaptability to unforeseen kinematic constraints or highly dynamic environments
- Performance may degrade when using open-source language models instead of proprietary LLMs and VLMs
What Comes Next
- Integrating adaptive execution mechanisms, such as reinforcement learning or differentiable motion planning, to allow atomic actions to be adapted at deployment time
- Incorporating more sophisticated perception and grounding modules to improve performance in tasks with novel objects, complex textures, or highly dynamic scenes
Sources: