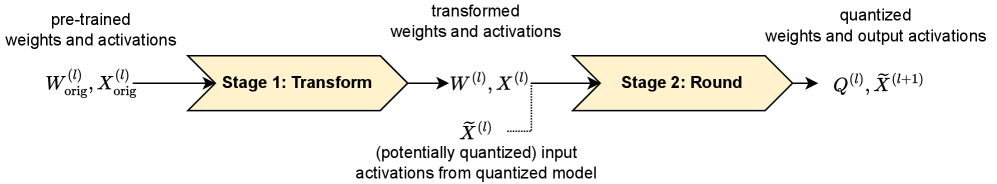Story
Qronos: Correcting the Past by Shaping the Future... in Post-Training Quantization
Key takeaway
Researchers developed Qronos, a new algorithm that can correct errors in AI models during the final quantization stage, potentially improving model efficiency without sacrificing performance. This could lead to more compact and powerful AI models for real-world applications.
Quick Explainer
Qronos is a new post-training quantization algorithm that addresses a key challenge in efficient inference of large language models - correcting quantization errors in both weights and activations, as well as residual errors propagated from previous quantized layers. Qronos uses an iterative optimization framework, alternating between selecting optimal quantized weights and updating unquantized weights to compensate for rounding errors. This approach is more comprehensive than previous techniques like OPTQ, which only correct weight quantization error implicitly. Qronos demonstrates performance advantages over existing data-driven quantization methods, especially as the quantization task becomes more challenging, such as when quantizing both weights and activations.
Deep Dive
Technical Deep Dive: Qronos for Correcting Quantization Errors in Language Models
Overview
Qronos is a new post-training quantization (PTQ) algorithm that corrects errors from both weight and activation quantization, as well as residual quantization errors propagated from previously quantized layers. Qronos is based on an interpretable optimization framework that outperforms existing data-driven approaches like OPTQ and GPFQ.
Problem & Context
Recent advances in PTQ have enabled efficient inference of large language models (LLMs) using few-bit weights and activations. Existing work focuses on two key aspects:
- Transformations that make weights and/or activations more amenable to quantization, such as using scaling invariances or orthogonal rotations.
- Rounding schemes that minimize quantization error, often using data-driven discrete optimization.
Qronos primarily addresses the second aspect - it introduces a new rounding algorithm that explicitly corrects quantization errors across the entire model.
Methodology
Qronos alternates between two steps:
- Selecting the optimal quantized weight that corrects the current quantization error, holding the remaining weights fixed.
- Updating the unquantized weights to optimally compensate for the rounding error.
This process is applied iteratively, with Qronos proving an equivalent formulation that significantly improves runtime and memory efficiency compared to a direct implementation.
Qronos also provides a novel interpretation of the previous OPTQ algorithm, showing that it implicitly corrects the cumulative weight quantization error over all previous iterations.
Data & Experimental Setup
The authors evaluate Qronos on the Llama3 and Qwen3 model families, using the WikiText2 dataset for evaluation. They compare Qronos against several baselines, including RTN, OPTQ, GPFQ, and GPTAQ.
The experiments isolate the impact of the rounding function by applying various quantization transforms (e.g. Hadamard-based incoherence processing, weight magnitude reduction) as the first stage in the quantization pipeline.
Results
Qronos consistently outperforms the baselines across a range of quantization scenarios:
- For weight-only quantization of Llama3 models, Qronos provides up to 1.4x improvement in perplexity and +3.3% increase in zero-shot accuracy over OPTQ.
- For weight-only quantization of Qwen3 models, Qronos yields the best results, surpassing the baselines.
- For weight-activation quantization of Llama3 models, Qronos again provides the highest quality quantized models.
The authors observe that Qronos demonstrates larger relative improvements as the quantization task becomes more challenging, such as when transitioning from weight-only to weight-activation quantization.
Interpretation
The authors attribute Qronos' performance advantages to its ability to explicitly correct quantization errors in both weights and activations, as well as residual errors propagated from previously quantized layers. In contrast, OPTQ only corrects weight quantization error.
The novel interpretation of OPTQ shows that it implicitly corrects the cumulative weight quantization error, but does not address activation mismatch or residual errors - limitations that Qronos addresses.
Limitations & Uncertainties
The experiments focus on the scaled min-max quantization grid, and the authors note that further improvements may be possible by leveraging more sophisticated weight and activation distributions.
Additionally, the runtime analysis is limited to a single linear layer microbenchmark, and the authors do not provide full end-to-end inference performance metrics.
What Comes Next
Future work could explore:
- Extending Qronos to handle non-uniform quantization grids and vector quantization.
- Integrating Qronos with state-of-the-art quantization transforms beyond the ones studied.
- Providing a comprehensive end-to-end runtime and throughput analysis on large language models.