Story
FeatBench: Towards More Realistic Evaluation of Feature-level Code Generation
Key takeaway
Researchers developed FeatBench, a new benchmark to more realistically evaluate how well AI systems can generate code for specific software features, which is important for improving the practical capabilities of generative AI in real-world programming.
Quick Explainer
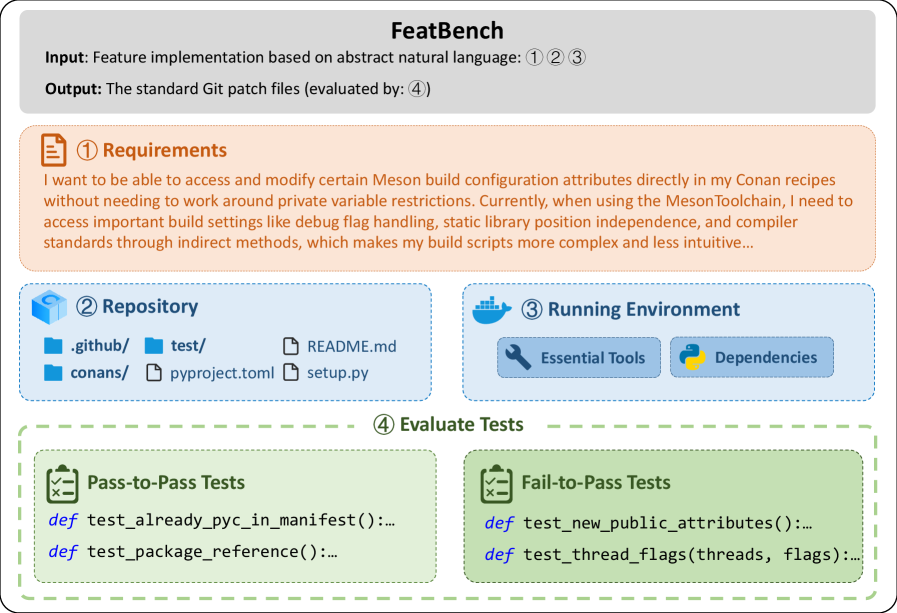
FeatBench is a novel benchmark designed to evaluate the performance of AI agents on realistic feature-level code generation tasks. Unlike existing benchmarks, FeatBench uses only natural language requirements, mirroring real-world software development scenarios where agents must independently bridge the gap between abstract intent and concrete code changes. FeatBench also employs an evolving data pipeline to construct new benchmark versions from the latest open-source repositories, effectively mitigating data contamination issues. This two-pronged approach - realistic task inputs and evolving data - aims to provide a more accurate assessment of an agent's ability to generate patches that both implement the desired functionality and maintain system stability.
Deep Dive
Technical Deep Dive: FeatBench - Towards More Realistic Evaluation of Feature-level Code Generation
Overview
FeatBench is a novel benchmark designed to evaluate the performance of large language models (LLMs) on realistic feature-level code generation tasks. Unlike existing benchmarks that rely on unrealistic task inputs (e.g., function signatures) and static datasets prone to data leakage, FeatBench introduces two key advancements:
- Realistic Task Inputs: FeatBench uses only natural language requirements, strictly devoid of code hints, to mirror realistic software development scenarios where agents must independently bridge the gap between abstract user intent and concrete code changes.
- Evolving Data: FeatBench employs an automated pipeline to construct new benchmark versions from the latest repositories, effectively mitigating data contamination issues that plague static benchmarks.
Methodology
Data Collection and Curation
FeatBench's data is sourced from 27 actively maintained open-source repositories, covering a diverse range of domains including AI/ML, DevOps, Web development, and more. The data curation process involves a multi-level filtering pipeline to ensure high quality:
- Repository-level: Repositories must have at least 3 formal releases and an identifiable test suite to guarantee verifiability. Non-production repositories (e.g., tutorials) are excluded.
- Release-level: Releases are filtered to include only those created within the last year, longer than 30 characters, and not automatically generated.
- PR-level: Retained PRs must modify at least one Python file, include new or modified test cases, and strictly change existing functions without adding or deleting functions.
Environment Configuration and Test Validation
FeatBench uses an automated two-stage pipeline to configure the runtime environment and validate the test cases:
- Environment Analysis: This agent locates crucial configuration files (e.g., CI/CD, dependencies) and determines the appropriate Python version for each task.
- Environment Configuration: Operating within a container, this agent uses caching and a high-performance package manager to systematically install dependencies and make the test suite executable.
Finally, FeatBench validates each task's correctness using a rigorous dual-validation approach:
- Fail-to-Pass (F2P) Tests: These test cases, introduced in the current PR, are expected to transition from failing to passing when the agent-generated patch is applied.
- Pass-to-Pass (P2P) Tests: These tests, derived from the repository's existing test suite, must continue to pass after applying the agent's patch to ensure backward compatibility.
Evaluation Metrics
FeatBench adopts the following key metrics:
- Resolved Rate (%): The percentage of tasks an agent successfully completes.
- Patch Apply Rate (%): The proportion of generated patches that are syntactically correct and can be applied without errors.
- File-level Localization Success Rate (%): The accuracy of the agent in modifying the correct set of files.
- Feature Validation Pass Rate (%): The pass rate of the F2P test cases, evaluating the correctness of the feature implementation.
- Regression Tests Pass Rate (%): The pass rate of the P2P test cases, ensuring system stability.
- Tokens Cost: The average number of tokens consumed per task.
Results
RQ1: Performance Evaluation on FeatBench
The evaluation on FeatBench reveals that the benchmark poses a significant challenge for SOTA agent-LLM configurations:
- The top-performing Trae-agent with GPT-5 achieves a Resolved Rate of only 29.94%.
- Autonomous planning-based agents like Trae-agent substantially outperform rigid pipeline-based ones like Agentless across key metrics.
- However, all configurations exhibit a universal issue: a low Regression Tests Pass Rate, indicating a high risk of introducing regressions while implementing new features.
RQ2: Factors Influencing Resolved Rate
FeatBench performance is heavily constrained by both repository and patch complexity:
- At the repository level, resolved rates degrade sharply from 60-70% for small repositories (< 200 files or 50k LOC) to only 10-30% for large ones (> 800 files or 300k LOC).
- At the patch level, success rates peak for single-file patches and those between 1-30 LOC, but collapse for substantial modifications exceeding 50 LOC or spanning more than 5 files.
- Importantly, the consistent performance across different task creation periods validates the absence of data leakage.
RQ3: Case Study of Failure Reasons
Manual analysis of 122 failed cases reveals that the predominant reason (73.6%) is Regressive Implementation, driven by a behavioral pattern of "aggressive implementation":
- Instead of strictly adhering to the user's requirements, agents tend to exhibit "scope creep" by proactively extending features or refactoring code beyond the explicit intent.
- This aggressive behavior can sometimes lead to architectural improvements that surpass human-written patches, but more often introduces defects that break existing functionality.
Limitations and Uncertainties
- The current scope of FeatBench is limited to Python repositories; extending it to other programming languages remains future work.
- While the test-based evaluation provides a robust ground truth, there is a potential risk of false positives where incorrect code passes sparse test suites by chance.
- The human-generated natural language requirements may still harbor some ambiguity or omissions, despite the rigorous validation process.
What Comes Next
Future work on FeatBench includes:
- Expanding the benchmark to cover a broader range of programming languages beyond Python.
- Exploring mechanisms to better align agent behaviors with realistic engineering practices, balancing strict adherence to specifications and the capability for robust software design.
- Investigating techniques to control the level of "aggressive implementation" exhibited by agents, harnessing its benefits while preventing harmful "scope creep" and regressions.