Story
On the Equivalence of Random Network Distillation, Deep Ensembles, and Bayesian Inference
Key takeaway
New algorithm advances could make AI systems more transparent about their uncertainty, potentially improving the safety and reliability of AI in real-world applications.
Quick Explainer
This work establishes a deep connection between three prominent uncertainty quantification techniques for deep learning: random network distillation (RND), deep ensembles, and Bayesian inference. At a high level, the key insight is that RND's uncertainty estimates are mathematically equivalent to the predictive variance of deep ensemble models in the limit of infinitely wide neural networks. Furthermore, by carefully designing the RND target function, the method can be made to directly match the Bayesian posterior predictive distribution, enabling efficient posterior sampling. This unification provides a conceptual foundation for understanding the relationship between these disparate approaches and suggests opportunities for incorporating prior knowledge into computationally efficient uncertainty quantification.
Deep Dive
Technical Deep Dive: On the Equivalence of Random Network Distillation, Deep Ensembles, and Bayesian Inference
Overview
This paper establishes a unified theoretical understanding of random network distillation (RND), a lightweight technique for uncertainty quantification in deep learning. The key findings are:
- RND's uncertainty estimates are mathematically equivalent to the predictive variance of deep ensembles in the infinite-width neural network regime.
- By modifying the RND target function, the RND error signal can be made to directly match the posterior predictive distribution of a Bayesian model with the neural tangent kernel (NTK) as the prior.
- This "Bayesian RND" variant enables an efficient posterior sampling procedure, producing independent samples from the exact Bayesian posterior predictive distribution.
Methodology
The analysis is conducted in the limit of infinitely wide neural networks, where network dynamics can be characterized using the neural tangent kernel (NTK) framework. Key steps:
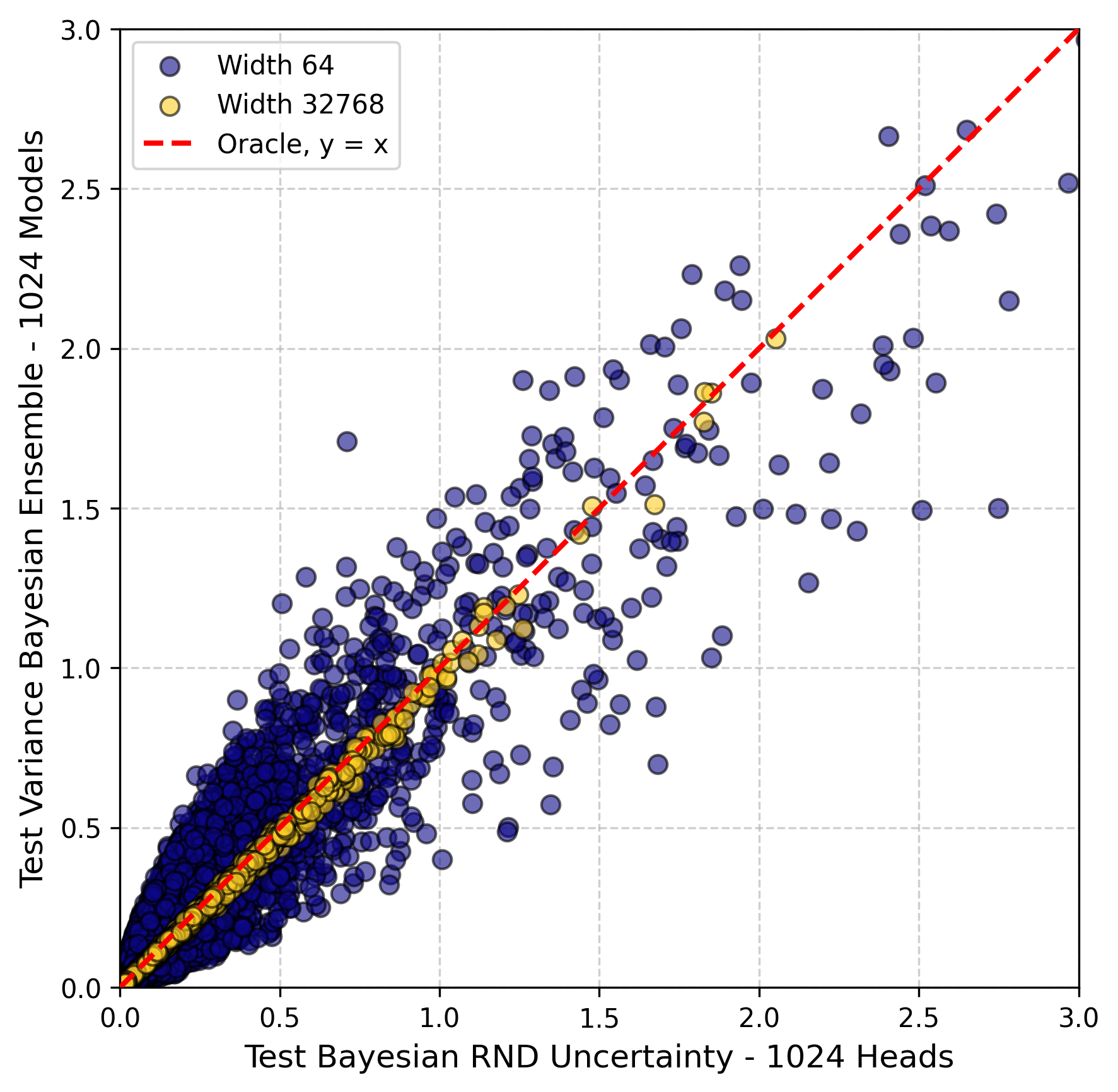
- Prove that standard RND's squared prediction errors exactly match the predictive variance of deep ensembles in this infinite-width regime.
- Engineer a modified "Bayesian RND" target function such that its error distribution aligns with the exact Bayesian posterior predictive distribution.
- Leverage the independence properties of multi-headed RND architectures to devise a posterior sampling algorithm using Bayesian RND.
Results
- Ensemble Equivalence: The squared errors of standard RND are mathematically equivalent to the predictive variance of deep ensembles in the infinite-width limit.
- Posterior Equivalence: By designing a specific RND target function, the RND error signal can be made to directly match the centered Bayesian posterior predictive distribution.
- Posterior Sampling: A multi-headed Bayesian RND model can be used to efficiently generate i.i.d. samples from the exact Bayesian posterior predictive distribution.
Limitations & Uncertainties
- The analysis is limited to the idealized setting of infinitely wide neural networks, which may not fully capture the behavior of practical, finite-width models.
- The impact of deviations from the NTK regime, such as feature learning, on the established equivalences remains an open question.
- The proposed Bayesian RND approach has only been validated numerically, and its practical implications require further investigation.
What Comes Next
- Characterizing the relationship between RND, ensembles, and Bayesian posteriors in realistic, finite-width settings.
- Exploring target function engineering as a general strategy for incorporating prior knowledge into computationally efficient uncertainty quantification methods.
- Investigating the application of Bayesian RND for principled Bayesian inference in deep learning.