Story
EduResearchBench: A Hierarchical Atomic Task Decomposition Benchmark for Full-Lifecycle Educational Research
Key takeaway
Researchers developed a new benchmark to evaluate how well AI language models can assist in scholarly writing tasks like research summaries, experimental designs, and data analysis. This could improve AI tools for academic researchers.
Quick Explainer
EduResearchBench is a comprehensive evaluation framework that assesses the capability of language models in the complex domain of educational academic writing. It decomposes the research workflow into a hierarchical taxonomy of specialized modules and fine-grained tasks, enabling granular diagnostics across the full lifecycle. This structured approach overcomes the limitations of existing benchmarks, which focus on general writing or single-shot text generation. By constructing a dataset of high-quality instruction-response pairs, EduResearchBench provides a more reliable and interpretable evaluation mechanism compared to holistic scoring. The distinctive aspect is the focus on modeling the nuanced stages of educational research, rather than solely text generation quality.
Deep Dive
Technical Deep Dive: EduResearchBench: A Hierarchical Atomic Task Decomposition Benchmark for Full-Lifecycle Educational Research
Overview
EduResearchBench is a comprehensive evaluation platform dedicated to assessing the capabilities of large language models (LLMs) in the domain of educational academic writing. It addresses key limitations of existing writing benchmarks by decomposing the complex research workflow into a hierarchical taxonomy of specialized research modules and fine-grained atomic tasks. This structured approach enables precise diagnostics of model performance throughout the full lifecycle of educational research and writing.
Problem & Context
While LLMs are increasingly applied in AI-powered academic assistance, rigorously evaluating their capabilities in scholarly writing remains a major challenge. Current benchmarks primarily focus on general writing tasks or single-shot text generation, failing to capture the high cognitive load, logical consistency, and domain-specific norms required for educational research workflows.
Methodology
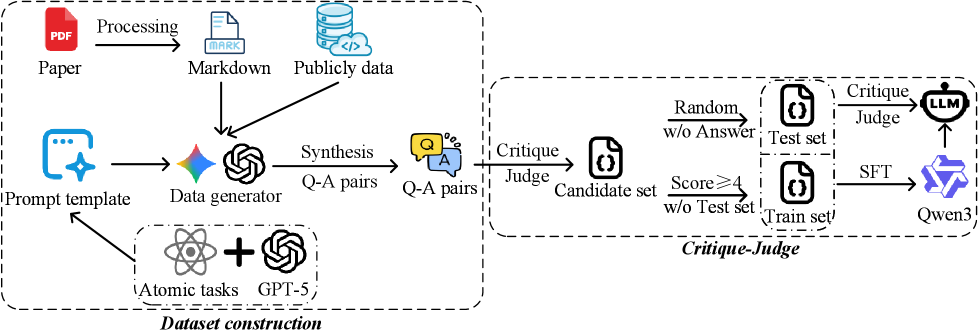
The EduResearchBench framework is built upon a Hierarchical Atomic Task Decomposition (HATD) taxonomy, which structures the educational research lifecycle into:
- 6 specialized research modules (e.g., Quantitative Analysis, Qualitative Research, Policy Analysis)
- 24 fine-grained atomic tasks (e.g., Hotspot Extraction, Variable Operationalization, Trustworthiness Statement)
This granular decomposition enables an automated evaluation pipeline that diagnoses model performance at the atomic task level, overcoming the limitations of holistic scoring.
Data & Experimental Setup
- EduResearchBench is constructed from over 55,000 raw academic samples, which are curated into 11,000 high-quality instruction-response pairs.
- A dual-model critique-and-judge filtering mechanism is employed to ensure the reliability of the evaluation data.
- The benchmark includes a Reference set with ground-truth answers and an Inference set for zero-shot generation assessment.
Results
Experiments show that EduWrite, a specialized educational writing model fine-tuned on the EduResearchBench dataset, substantially outperforms larger general-purpose LLMs on multiple core metrics. This result demonstrates that in vertical domains, data quality density and hierarchically staged training curricula are more decisive than parameter scale alone.
Interpretation
EduResearchBench reveals stage-wise capability differences across the educational research lifecycle. For example, current frontier models excel in language-quality assessment (Reviewer module) but struggle more with methodological reasoning (Quantitative Research module). This pattern supports the need for fine-grained diagnostics to uncover specific capability bottlenecks.
Limitations & Uncertainties
- The benchmark is currently limited to the education domain and may not generalize to other academic disciplines.
- The automated evaluation protocol, while more interpretable than holistic scoring, may still diverge from human expert judgment in edge cases.
- The construction of high-quality training data remains a significant challenge and potential source of bias.
What Comes Next
- Expanding EduResearchBench to cover a broader range of academic domains beyond education.
- Developing more advanced evaluation mechanisms that better approximate human review processes.
- Exploring novel training strategies and architectural innovations tailored to complex academic writing tasks.