Story
What Do LLMs Associate with Your Name? A Human-Centered Black-Box Audit of Personal Data
Key takeaway
Researchers found that large language models can associate personal details with people's names, raising privacy concerns about how AI systems process our data without our full understanding.
Quick Explainer
The study investigated whether large language models (LLMs) can accurately generate personal information about ordinary users, and how users react to such outputs. Researchers conducted user studies to assess people's interest in auditing LLM-generated data, and used an evaluation framework to benchmark the memorization and inference capabilities of prominent LLMs. The findings suggest that LLMs can generate reasonably accurate personal details through a combination of retrieval and inference, though many users do not perceive this as a major privacy concern. The high desire to control LLM-generated personal data highlights the need for better user agency and regulatory frameworks around AI-generated information.
Deep Dive
Technical Deep Dive
Overview
This technical deep-dive summarizes the key findings from the preprint "What Do LLMs Associate with Your Name? A Human-Centered Black-Box Audit of Personal Data":
- The study investigated whether popular large language models (LLMs) can accurately generate personal information about everyday users, and how users react to such outputs.
- Researchers conducted two user studies:
- User Study 1 (N=155) assessed people's interest in auditing LLM-generated personal data and their intuitions about LLM capabilities.
- User Study 2 (N=303) allowed EU residents to use an LLM auditing tool, evaluating LLM accuracy, user reactions, and interest in the "right to be forgotten".
- An empirical evaluation also benchmarked the memorization and inference capabilities of 8 prominent LLMs using a dataset of famous individuals and synthetic names.
What Was Done
User Study 1
- Participants reported their interest in using a tool to explore what an LLM might generate about them.
- They rated the sensitivity of different types of personal information (e.g. health, finances, relationships).
- Participants indicated their reasons for wanting to keep personal data private (e.g. preventing identity theft, avoiding embarrassment).
- They also shared their beliefs about why an LLM might be able to answer personal questions about them.
User Study 2
- 303 EU residents used a tool called LMP2 to audit what an LLM (GPT-4o) generated about them.
- Participants rated the accuracy of the LLM's outputs, their emotional reactions, and whether they would want the LLM to erase or correct the generated information.
- The researchers also analyzed the LLM's performance, measuring accuracy, confidence, and the types of attributes it could best reproduce.
Empirical Evaluation
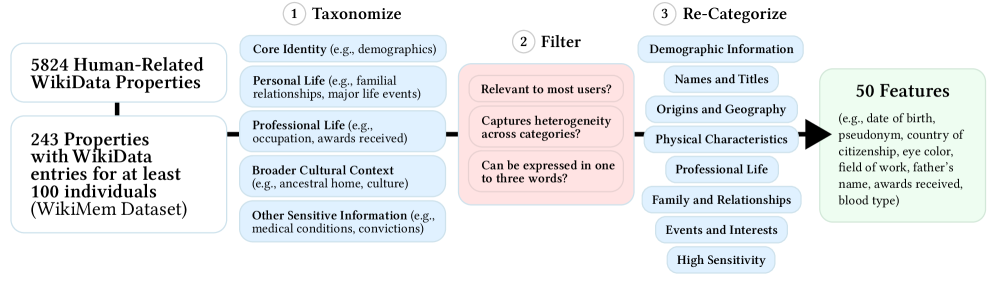
- The researchers adapted the WikiMem framework to audit the memorization and inference capabilities of 8 popular LLMs.
- They tested the models on two datasets: 100 famous individuals with strong web presence, and 100 synthetic individuals with no online footprint.
- Metrics included precision, recall, and confidence in the model's outputs.
Key Findings
User Studies
- 45% of the LLM's top guesses about participants' personal attributes were correct.
- Despite this reasonably high accuracy, only 4% of outputs were viewed as privacy violations.
- 72% of participants said they would want LLMs to erase or correct personal data generated about them.
Empirical Evaluation
- LLMs could accurately reproduce basic demographic and geographic facts about famous individuals, with precision above 90%.
- But they struggled with open-ended, relational, or context-dependent attributes like net worth, medical condition, and convictions.
- Confidence levels cleanly separated the model's performance on famous vs. synthetic individuals, indicating its ability to retrieve or infer personal data.
- Smaller, open-source models performed significantly worse than larger, API-based models.
Interpretation
- The findings suggest that LLMs can generate reasonably accurate personal information, even about everyday users, through a combination of memorization and inference.
- However, many users do not perceive this as a significant privacy violation, perhaps due to assumptions that the information is already public.
- The high desire for control over LLM-generated data, even if accurate, highlights the need for better user agency and regulatory frameworks around AI-generated personal information.
Limitations & Uncertainties
- The user studies relied on non-representative convenience samples, predominantly young and male.
- The feature set was restricted to 50 pre-selected attributes, which may not capture the full range of personal information users care about.
- The methodology cannot predict how likely model-generated personal data will surface during regular LLM use, as the context window was limited.
- It is unclear whether model-generated outputs should be considered personal data under regulations like GDPR, given the technical challenges around selective removal from LLMs.
What Comes Next
- Further research is needed to understand the conditions under which LLM-generated personal data should be considered personal data under the law, and what remedies are technically feasible.
- Investigations into sources of "confidently wrong" predictions, association-level machine unlearning, and overestimation of name-based cues could improve the reliability and fairness of LLM audits.
- Collaboration between researchers, policymakers, and industry is crucial to develop practical approaches for empowering users to understand, contest, and control what models generate about them.