Story
PETS: A Principled Framework Towards Optimal Trajectory Allocation for Efficient Test-Time Self-Consistency
Key takeaway
A new framework called PETS helps AI models perform more consistently during testing, which could lead to more reliable and effective AI systems in real-world applications.
Quick Explainer
PETS is a framework that optimizes test-time scaling by efficiently allocating computational resources across different questions. It leverages the intrinsic structure of self-consistency, which measures the agreement between majority voting with a finite budget and the population majority label. PETS defines an allocation policy that distributes the total budget to maximize the aggregate self-consistency rate, rather than allocating uniformly. This is done by modeling each reasoning trace as a noisy worker label and using a Bayesian framework to estimate the optimal budget allocation, either globally in the offline setting or greedily in the online streaming setting.
Deep Dive
Technical Deep Dive: PETS for Efficient Test-Time Self-Consistency
Overview
PETS (Principled and Efficient Test-Time Self-Consistency) is a framework for optimizing test-time scaling by efficiently allocating computational resources across different questions. The key idea is to leverage the intrinsic structure of self-consistency to distribute sampling effort according to the relative difficulty of different questions, rather than allocating uniformly.
PETS defines a new performance metric called self-consistency rate, which measures the probability that majority voting with a finite budget matches the population majority. By optimizing this metric, PETS can substantially reduce the number of required samples to reach full self-consistency, while maintaining or improving accuracy.
The paper studies PETS in two settings:
- Offline Batch: The full question set is available upfront, allowing the allocation to adapt globally.
- Online Streaming: Questions arrive sequentially, and allocation decisions must be made immediately without seeing future questions.
Methodology
Self-Consistency and Optimal Trajectory Allocation
The paper introduces the self-consistency rate, which measures the agreement between majority voting with a finite budget B and the population majority label obtained in the infinite-sample limit.
For a question q_i, the self-consistency rate is defined as:
$\mathrm{SC}(qi; B) = \mathbb{P}(Yi^{\mathrm{Maj}}(B) = y_i^{\infty})$
where $Yi^{\mathrm{Maj}}(B)$ is the majority vote with budget B, and $yi^{\infty}$ is the population majority label.
The goal is to find an allocation policy $\pi$ that distributes the total budget $B_{\text{total}}$ across the questions to maximize the aggregate self-consistency rate.
Offline PETS
In the offline setting, the full question set is available upfront. PETS-Offline connects the trajectory allocation problem to the well-studied crowdsourcing literature, where each reasoning trace is modeled as a noisy worker label.
The paper adopts a Bayesian framework that maintains a posterior distribution over the answer distribution parameters $\bm{\theta}i$ for each question $qi$. It then uses the Optimistic Knowledge Gradient (OKG) policy to sequentially allocate additional samples to the questions with the largest expected one-step improvement in terminal self-consistency.
Online PETS
In the online streaming setting, questions arrive sequentially, and allocation decisions must be made immediately without seeing future questions. PETS-Online addresses this by:
- Estimating a prior distribution over question difficulties from a warm-up training set.
- Solving a constrained optimization problem to determine the optimal budget allocation across difficulty levels.
- Greedily allocating the per-question budgets determined by the optimization upon arrival of each new question.
This one-shot allocation strategy can be cast as a supervised learning problem, where the goal is to predict the optimal budget given the question difficulty.
Results
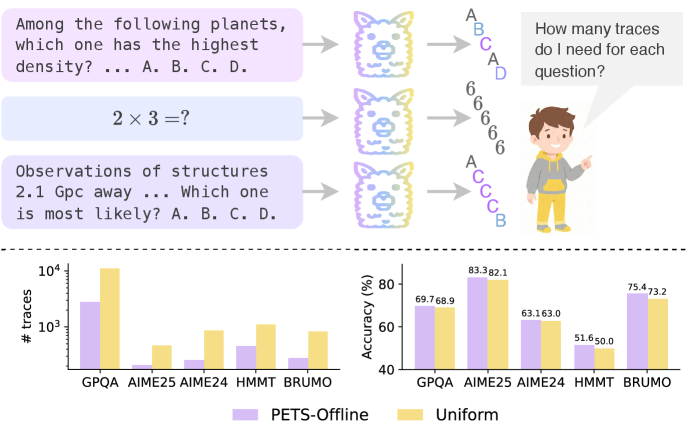
The paper evaluates PETS on several well-known knowledge and reasoning benchmarks, including GPQA, AIME 24/25, HMMT, and BRUMO, using state-of-the-art language models like Qwen3 and GPT-OSS.
Key findings:
- Compared to uniform allocation, PETS-Offline reduces the number of traces required to reach full self-consistency by up to 75%, while achieving higher self-consistency at any given budget.
- PETS-Online closely matches the performance of the oracle PETS-Oracle variant that has access to the true question difficulties, indicating the effectiveness of the online estimation procedure.
- Confidence-weighted majority voting further improves accuracy by reshaping the population majority towards the ground truth.
Limitations and Uncertainties
- The paper assumes the availability of a warm-up training set to estimate the prior distribution over question difficulties in the online setting. In practice, this may not always be the case.
- The analysis focuses on multiple-choice or fill-in-the-blank tasks. Extending PETS to more open-ended generation tasks may require additional considerations.
- The paper does not explore the sensitivity of PETS to the quality of the confidence weighting scheme or the potential failure modes when the population majority is systematically wrong.
Future Work
Promising directions for future research include:
- Investigating methods to directly predict the question difficulty parameters $\bm{\theta}$ from the question text, without relying on a warm-up phase.
- Extending PETS to handle a broader range of task types, such as open-ended generation or structured prediction problems.
- Analyzing the robustness of PETS under various types of model misspecification or distributional shift in the question difficulties.
- Exploring connections between PETS and other test-time scaling techniques, such as Best-of-N selection or strategic scaling, to develop more comprehensive efficient reasoning frameworks.