Story
Extending quantum theory with AI-assisted deterministic game theory
Key takeaway
Researchers developed an AI system that can predict individual runs of quantum experiments, potentially extending quantum theory by explaining contextuality and causality at a local level. This could advance our understanding of the fundamental nature of reality.
Quick Explainer
The authors propose a novel conceptual framework for modeling quantum experiments as deterministic games, where the experimental components (e.g., observers, particles) are "players" optimizing their rewards. By mapping quantum scenarios to extensive-form games with imperfect information, and using AI to learn the underlying reward functions, the framework can reproduce quantum phenomena like contextuality and non-locality, while operating within a local hidden-variable model. The key innovation is the "Perfectly Transparent Equilibrium" solution concept, which drops the assumption of "free choice" in favor of "perfect prediction" - allowing the framework to match quantum predictions without abandoning local realism.
Deep Dive
Technical Deep Dive: Extending Quantum Theory with AI-Assisted Deterministic Game Theory
Overview
This work proposes a novel AI-assisted framework for modeling quantum experiments using deterministic game theory. The key insight is that quantum scenarios can be mapped to extensive-form games with imperfect information, where the "players" are the experimental components (observers, particles, etc.) and their goal is to optimize their rewards. By learning the reward functions through AI methods, the authors demonstrate that their framework can reproduce quantum phenomena such as contextuality and non-locality, while still operating within a deterministic local hidden-variable model.
Problem & Context
Historically, no-go theorems like Bell's inequality have been interpreted as showing that local hidden-variable models are incompatible with quantum mechanics. However, these conclusions rely on an implicit assumption of "free choice" - that the observers can freely choose which measurements to perform, independent of any hidden variables.
The authors argue that by framing quantum experiments as deterministic games, they can retain local hidden variables while still matching quantum predictions. The key is to give up the notion of "free choice" and instead assume "perfect prediction" - that the players can accurately predict each other's decisions. This allows the framework to obey the constraints of no-go theorems without requiring the abandonment of local realism.
Methodology
The authors' approach consists of the following steps:
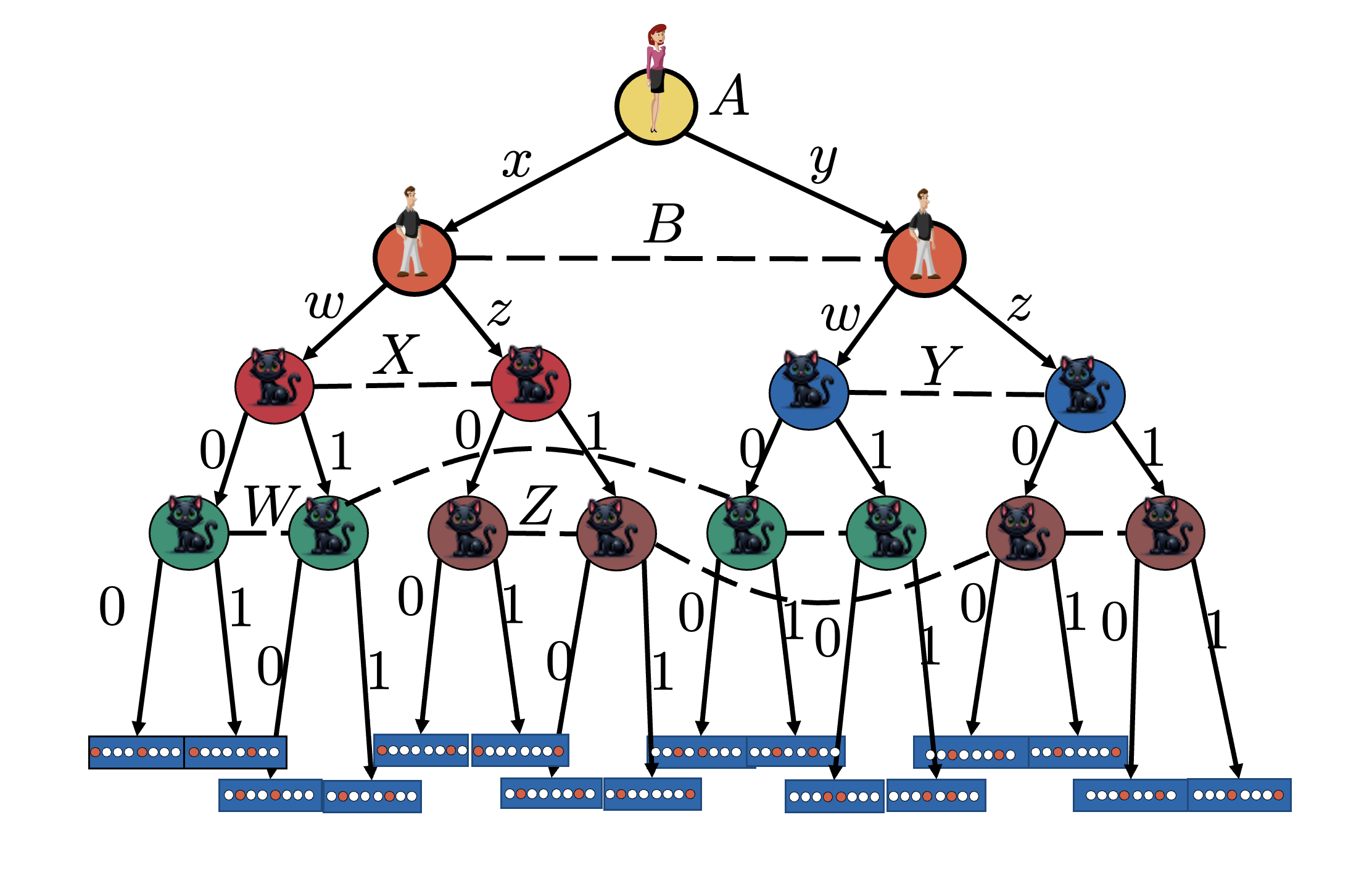
- Represent the structure of a quantum experiment as an extensive-form game with imperfect information.
- Design a "Perfectly Transparent Equilibrium" (PTE) solution concept that drops the assumption of unilateral deviations (free choice).
- Use AI to learn the reward functions that govern the players' decisions, by matching the observed statistics to quantum predictions.
- Demonstrate the framework on the canonical 2-2-2 EPR experiment, showing it can closely reproduce the quantum predictions while operating deterministically.
The key innovations are the game-theoretic formulation, the PTE solution concept, and the AI-assisted reward learning approach.
Data & Experimental Setup
The authors focus their experiments on the 2-2-2 version of the EPR experiment, where there are 2 players, 2 measurement choices per player, and 2 possible outcomes.
They represent the experiment as an extensive-form game, with imperfect information modeled via dashed lines. The players' goal is to optimize their rewards, which are represented by an unknown but learnable parameterized function (a neural network).
Results
The authors demonstrate that their framework can closely match the quantum predictions for the 2-2-2 EPR experiment, even though it operates deterministically without free choice. The learned reward functions allow the framework to violate Bell's inequality, a key signature of quantum non-locality.
The authors provide a figure showing the close agreement between the histogram of observed outcomes and the quantum-predicted statistics.
Interpretation
The authors interpret their results as a "proof-of-concept" for a local hidden-variable theory that can extend quantum theory. By giving up the notion of free choice and instead assuming perfect prediction, they are able to retain local realism while still reproducing key quantum phenomena.
They argue that further expanding their framework to a wider range of quantum experiments will help them infer the underlying local hidden-variable theory they are seeking.
Limitations & Uncertainties
The authors acknowledge several limitations:
- The reward learning approach relies on a finite number of simulation runs, leading to minor discrepancies with the quantum predictions.
- The reward ansatz was inspired by Bell's original work, and may not generalize well to more complex quantum experiments.
- An analytical approach for deriving the reward functions remains an open problem.
They also note that while their framework drops the assumption of free choice, it introduces the potentially more subtle assumption of "perfect prediction".
What Comes Next
The authors propose several next steps to further develop their framework:
- Expanding to more complex quantum experiments beyond the 2-2-2 EPR setup.
- Exploring alternate reward learning approaches, such as symbolic regression.
- Investigating the physical meaning of the learned reward functions to gain insight into the underlying local hidden-variable theory.
Overall, the authors present a promising new direction for reconciling local realism with quantum mechanics, using AI-assisted game theory as a tool for exploring the foundations of quantum theory.