Story
SIT-LMPC: Safe Information-Theoretic Learning Model Predictive Control for Iterative Tasks
Key takeaway
New machine learning algorithm helps robots safely complete complex, real-world tasks more effectively.
Quick Explainer
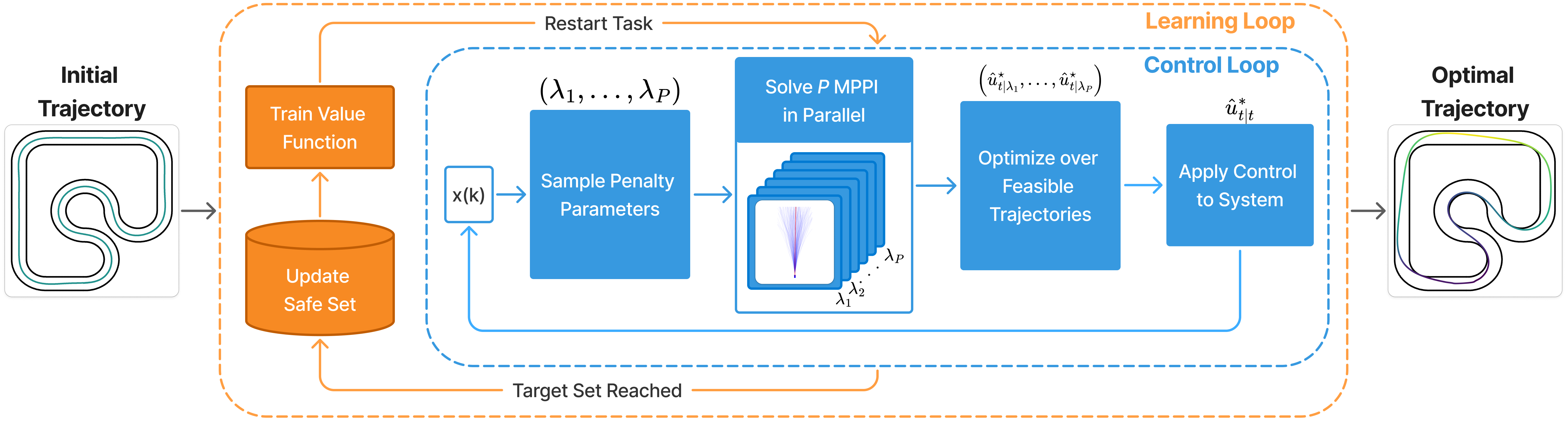
SIT-LMPC is a novel control framework that enables safe and efficient iterative task execution for complex, uncertain robotic systems. It combines Learning Model Predictive Control (LMPC) with an information-theoretic Model Predictive Path Integral (MPPI) controller and an adaptive constraint penalty method. SIT-LMPC iteratively learns a value function model using flexible normalizing flows to capture complex uncertainty, while parallelizing control sampling and penalty parameter tuning for real-time performance. This integration of LMPC, MPPI, and adaptive penalties allows SIT-LMPC to handle general nonlinear, stochastic systems with state constraints, outperforming prior LMPC approaches in both simulated and real-world experiments on autonomous vehicle tasks.
Deep Dive
Technical Deep Dive: SIT-LMPC for Safe and Efficient Iterative Tasks
Overview
SIT-LMPC is a safe, iterative learning control framework for stochastic, nonlinear dynamical systems. It extends the Learning Model Predictive Control (LMPC) approach to handle general state constraints by integrating an information-theoretic Model Predictive Path Integral (MPPI) controller with an online adaptive penalty method. Key features:
- Iteratively learns a value function model using normalizing flows to capture complex uncertainty
- Parallelizes control sampling and adaptive constraint penalty parameter tuning for real-time performance
- Demonstrated through simulations and real-world experiments on autonomous vehicle tasks, outperforming prior LMPC methods
Problem & Context
- Robots executing iterative tasks in complex, uncertain environments require control strategies that balance robustness, safety, and high performance
- Prior LMPC methods could only handle constrained linear systems or required restrictive assumptions for nonlinear systems
- MPPI is an information-theoretic MPC algorithm for stochastic systems, but does not natively handle state constraints
Methodology
- Formulate the constrained infinite-horizon optimal control problem for discrete-time nonlinear stochastic systems:
- Define admissible state and control sets, and a robust controlled invariant target set
- Minimize infinite-horizon stage cost subject to state/control constraints
- Extend LMPC to stochastic nonlinear systems:
- Iteratively construct a controlled invariant terminal constraint set from previous feasible trajectories
- Learn the value function using normalizing flows to model complex uncertainty
- Integrate MPPI with an online adaptive penalty method to solve the constrained finite-horizon problem:
- Convert constraints to penalty terms in the cost function
- Adaptively tune penalty parameters to balance optimality and constraint satisfaction
Data & Experimental Setup
- Benchmark experiments on:
- Deterministic linear point-mass navigation
- Autonomous racing with a stochastic, nonlinear, nonholonomic vehicle model
- Real-world 1/5 scale autonomous off-road racing vehicle
- Compared to LMPC and ABC-LMPC baselines
Results
- Deterministic point-mass: SIT-LMPC outperforms LMPC and ABC-LMPC in terms of convergence rate
- Simulated autonomous racing:
- ABC-LMPC frequently crashes due to CEM's susceptibility to noise and mode collapse
- SIT-LMPC consistently improves lap time while ensuring safety
- Real-world off-road racing:
- SIT-LMPC improves lap time by 31.4% over ABC-LMPC
- Handles model mismatch, imperfect localization, and environmental disturbances
Interpretation
- SIT-LMPC's combination of LMPC, MPPI, and adaptive penalties enables it to handle general nonlinear, stochastic systems with state constraints
- Modeling the value function with normalizing flows allows richer uncertainty representation compared to Gaussian priors
- Parallelizing control sampling and penalty parameter tuning is crucial for real-time performance
Limitations & Uncertainties
- Only evaluated up to 150 iterations - longer-term behavior and convergence properties not explored
- Real-world experiments limited to a single track and vehicle platform
- No analysis of how performance scales with problem dimensionality
What Comes Next
- Apply SIT-LMPC to a wider range of robotic platforms and task domains
- Investigate convergence guarantees and performance bounds for SIT-LMPC
- Explore integration with system identification and online model adaptation
Sources:
- [1] SIT-LMPC: Safe Information-Theoretic Learning Model Predictive Control for Iterative Tasks (arXiv preprint)