Story
A feature-stable and explainable machine learning framework for trustworthy decision-making under incomplete clinical data
Key takeaway
Researchers developed a machine learning system that can make trustworthy decisions using incomplete medical data, which could improve healthcare and diagnosis for patients.
Quick Explainer
CACTUS is a machine learning framework designed to provide trustworthy diagnostic support in biomedical domains with incomplete, heterogeneous data. Its key components include feature abstraction for improved interpretability, a modified Naive Bayes classifier for transparent decision-making, and systematic analysis of feature stability as data quality degrades. By quantifying how consistently informative features are preserved, CACTUS addresses a critical limitation of traditional predictive models, which can exhibit unreliable insights despite comparable accuracy. This stability-aware approach helps maintain confidence in the reliability and reproducibility of CACTUS's data-driven insights, even as real-world biomedical data faces challenges like missing values.
Deep Dive
Technical Deep-Dive: Feature-Stable Machine Learning for Trustworthy Bladder Cancer Diagnosis
Summary
This paper presents a novel machine learning framework called CACTUS (Comprehensive Abstraction and Classification Tool for Uncovering Structures) designed to address challenges in applying AI to small, heterogeneous, and incomplete biomedical datasets. Using a real-world bladder cancer cohort, the authors demonstrate that CACTUS achieves competitive predictive performance while maintaining significantly higher stability of top-ranked features as data missingness increases, including in sex-stratified analyses.
The key contributions are:
- CACTUS integrates feature abstraction, interpretable classification, and systematic feature stability analysis to quantify how consistently informative features are preserved as data quality degrades.
- CACTUS outperforms widely used ML approaches like random forests and gradient boosting in terms of balanced accuracy and recall, particularly for male and female subgroups.
- The authors highlight feature stability as a critical yet underutilized dimension of model evaluation, showing that predictive performance alone is insufficient to characterize model reliability.
- CACTUS offers a generalizable framework for trustworthy data-driven decision support in biomedical domains where incomplete, high-dimensional data and model transparency are critical.
Problem & Context
- Machine learning models are increasingly applied to biomedical data, yet their adoption in high-stakes domains remains limited by poor robustness, limited interpretability, and instability of learned features under realistic data perturbations like missingness.
- Biomedical datasets are frequently incomplete, heterogeneous, and subject to acquisition biases, raising concerns about the robustness and reproducibility of model-derived insights.
- There is a growing need for interpretable and explainable ML tools that can handle incomplete data, especially in sensitive domains like healthcare where trust and accountability are essential.
Methodology
- CACTUS integrates three key components:
- Feature abstraction: Transforms feature values into 2 categories (Up/Down) using ROC curves for improved interpretability and anonymization.
- Interpretable classification: Uses a modified Naive Bayes algorithm for transparent decision-making.
- Systematic feature stability analysis: Quantifies how consistently informative features are preserved as data quality degrades.
- CACTUS is benchmarked against popular ML methods like random forests, AdaBoost, XGBoost, LightGBM, and CatBoost on a bladder cancer cohort (HaBio) with controlled levels of randomly introduced missing data.
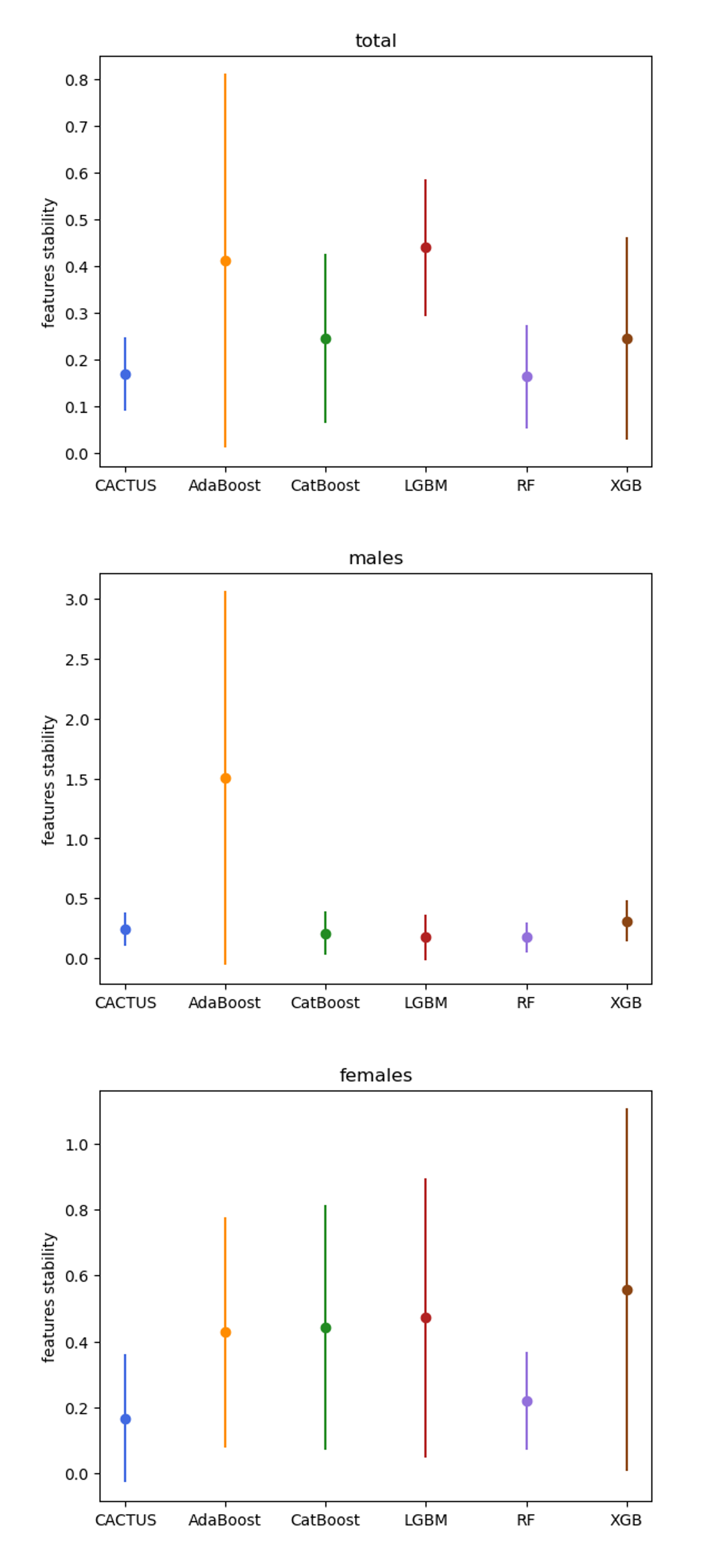
- Feature stability is measured using average relative change in feature importance and percentage overlap of top-ranked features across datasets with varying missingness.
Data & Experimental Setup
- The HaBio cohort includes 568 patients (201 bladder cancer, 367 non-bladder cancer) with 79 biomarkers and demographic/lifestyle features.
- The dataset is unbalanced, with 130 female (23%) and 438 male (77%) patients.
- Controlled levels of missing data (10%, 20%, 30%) are randomly introduced to simulate realistic data degradation scenarios.
- In addition to the full dataset (TOTAL), separate analyses are conducted for male (MALES) and female (FEMALES) subgroups.
Results
- CACTUS achieves competitive or superior predictive performance (balanced accuracy, recall) compared to other ML methods, especially for male and female subgroups.
- CACTUS demonstrates significantly higher stability of top-ranked features as missingness increases, with lower average relative change and higher overlap of top 10 features across datasets.
- The 10 most important features identified by CACTUS include known bladder cancer biomarkers like clusterin, VEGF, cystatin B, and sex-specific markers like haematuria and microalbuminuria.
- Feature stability provides complementary information to predictive performance, revealing that models with comparable accuracy can exhibit markedly different behavior in terms of feature consistency.
Interpretation
- The superior feature stability of CACTUS reinforces the trustworthiness of its predictions, as key informative features remain consistent even under data degradation.
- Sex-specific differences in top biomarkers suggest the need for tailored screening panels for males and females.
- Integrating multiple biomarkers into a diagnostic panel is preferable to relying on a single marker like BTA, which can be influenced by confounding factors like haematuria.
- Feature stability should be considered a critical dimension of model evaluation alongside traditional metrics like accuracy, as it provides insights into the reliability and reproducibility of data-driven insights.
Limitations & Uncertainties
- The thresholds calculated by CACTUS to abstract features are not the same as those set by medical institutions for diagnosis, as they represent the best values to separate the two classes (bladder cancer vs. non-bladder cancer).
- Larger datasets should be used to confirm the initial findings from the HaBio cohort.
- The relative contributions of biomarkers vs. lifestyle/demographic factors should be further investigated by dividing the dataset accordingly.
- Differential impacts of features across populations should be considered.
What Comes Next
- Apply the CACTUS framework to other biomedical domains facing similar challenges of incomplete, heterogeneous data and the need for interpretable, trustworthy AI systems.
- Explore the integration of CACTUS with other AI techniques (e.g., deep learning) to leverage their complementary strengths.
- Investigate the potential of CACTUS to guide the development of novel biomarker-based screening assays for bladder cancer and other diseases.
- Incorporate stability-aware evaluation as a standard component of pattern discovery pipelines operating on imperfect real-world data.