Story
LiveClin: A Live Clinical Benchmark without Leakage
Key takeaway
Researchers have developed a new live benchmark system called LiveClin that aims to provide a more reliable way to evaluate medical language models, by addressing issues like data contamination and knowledge obsolescence that can inflate scores on static benchmarks.
Quick Explainer
LiveClin is a novel medical benchmark designed to address critical limitations in existing large language model (LLM) evaluations for healthcare. It leverages a continuously refreshed corpus of contemporary, peer-reviewed clinical case reports to construct dynamic, multimodal clinical reasoning challenges that simulate the entire patient journey. This rigorous, three-stage pipeline - from case construction to exam generation and quality check - aims to overcome the challenges of data contamination and knowledge obsolescence that undermine the validity of traditional static benchmarks. By providing a clinically grounded, evolving assessment framework, LiveClin seeks to guide the development of medical LLMs towards greater real-world reliability and safety.
Deep Dive
Technical Deep Dive: LiveClin
Overview
LiveClin is a novel medical benchmark designed to address critical limitations in existing large language model (LLM) evaluations for healthcare. Developed by a team of AI researchers and medical experts, LiveClin overcomes the challenges of data contamination and knowledge obsolescence by leveraging a constantly refreshed corpus of contemporary, peer-reviewed clinical case reports.
Problem & Context
Reliable evaluation of medical LLMs is essential for their safe and effective integration into clinical practice. However, current benchmarks suffer from two major shortcomings:
- Data Contamination: As LLMs are trained on ever-expanding web-scale datasets, the questions and answers from popular static benchmarks are inevitably absorbed into their training, leading to inflated performance scores that do not reflect genuine progress.
- Knowledge Obsolescence: Clinical knowledge evolves rapidly, rendering the content of static benchmarks irrelevant over time.
These issues fundamentally undermine the validity of model evaluation, creating an "illusion of capability" and preventing the development of truly trustworthy medical AI systems.
Methodology
To address these challenges, the LiveClin team developed a rigorous, three-stage pipeline:
- Case Construction: Contemporary, peer-reviewed case reports from PubMed Central are curated and sampled to establish a continuously updated data foundation, ensuring clinical currency and resistance to contamination.
- Exam Generation: An iterative Generator-Critic architecture transforms the static case reports into dynamic, multimodal clinical reasoning challenges that simulate the entire patient journey.
- Quality Check: A multi-layered quality assurance protocol, combining AI pre-screening and physician verification, guarantees the factual accuracy and logical integrity of the resulting benchmark.
Data & Experimental Setup
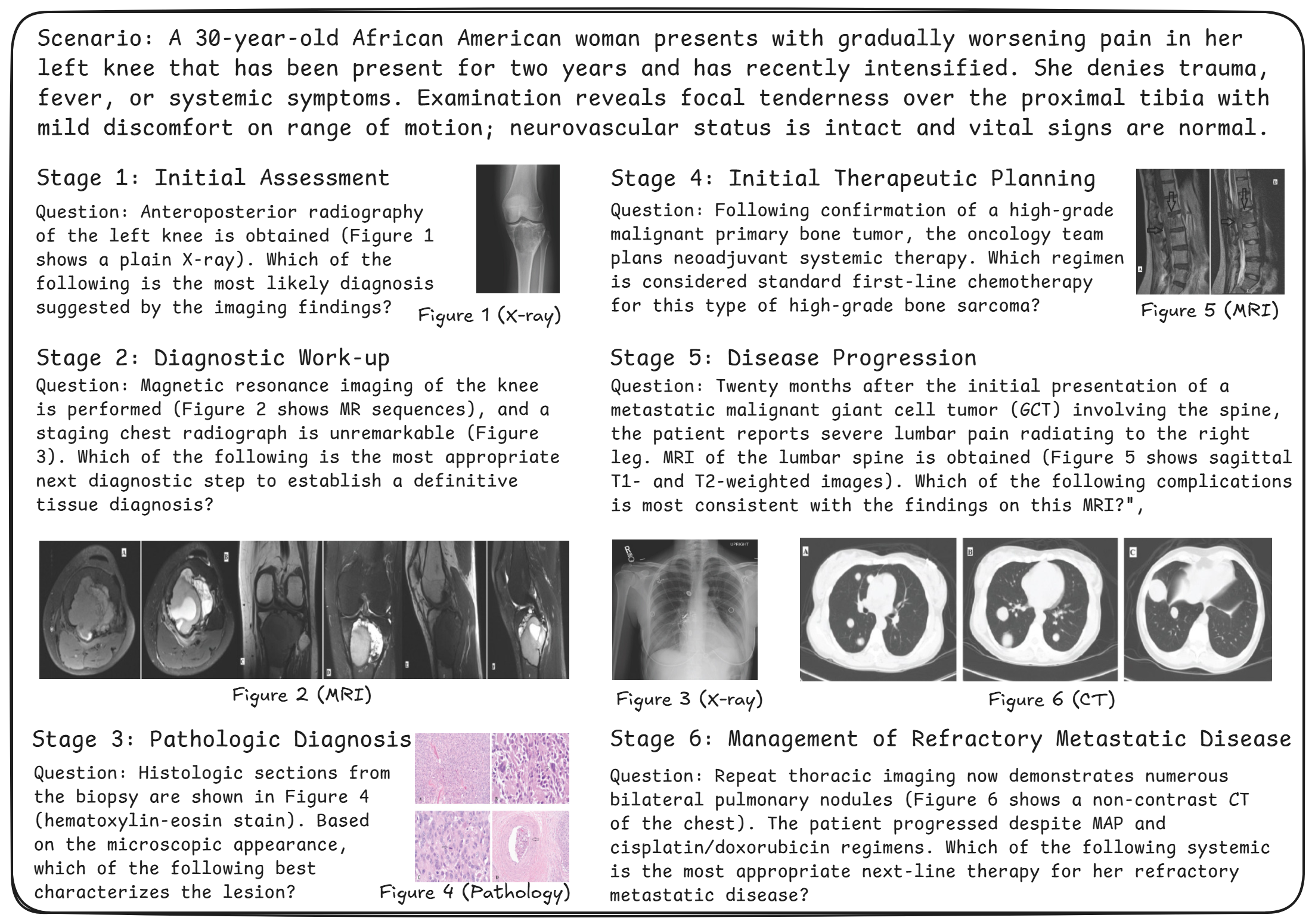
The final LiveClin benchmark comprises 1,407 unique clinical cases with 6,605 questions, spanning 16 ICD-10 chapters and 72 distinct disease clusters. All cases contain multimodal content, including 3,757 images and 634 tables, reflecting the diverse data sources encountered in real-world clinical practice.
The team evaluated 26 leading LLMs, including proprietary models, powerful open-source general LLMs, and specialized medical models. For a robust baseline, they also benchmarked human experts, including Chief Physicians, Associate Chief Physicians, and Attending Physicians.
Results
The evaluation revealed a stark performance gap, with the top-performing model achieving a Case Accuracy of just 35.7%. This highlights the profound difficulty of the real-world clinical scenarios in LiveClin, which challenge models' ability to integrate evolving information and navigate the entire patient journey.
The results also uncovered distinct failure modes across different model classes:
- Proprietary leaders struggle with mid-pathway reasoning, especially during the cognitively demanding Diagnosis & Interpretation stage.
- Open-source medical models exhibit late-stage breakdowns, failing to maintain long-term context during the less complex Follow-up phase.
- General-purpose models stumble early on, demonstrating weaknesses in effectively reasoning from the initial clinical presentation.
Notably, even the strongest models trail experienced clinicians, with Chief Physicians outperforming most AI systems.
Interpretation
The LiveClin benchmark marks a paradigm shift from static knowledge testing to the dynamic assessment of applied clinical reasoning. By providing a continuously evolving, clinically grounded challenge, it aims to guide the development of medical LLMs towards greater real-world reliability and safety.
The stark performance gaps uncovered by LiveClin highlight the critical need for targeted, domain-specific optimization in medical AI. Scaling or model upgrades alone are insufficient - building systems that can comprehensively manage complete clinical pathways will require aligning with expert-level reasoning and closing fundamental gaps in areas like long-term context retention and nuanced multimodal integration.
Limitations & Uncertainties
While LiveClin mitigates the challenges of data contamination and knowledge obsolescence, it inherits the potential biases of its data source, the PubMed Central repository. This corpus may underrepresent low-resource regions and certain rare conditions, limiting the global generalizability of the benchmark.
Additionally, the manual annotation process, though highly rigorous, could introduce subtle inconsistencies or subjectivities that impact the fine-grained performance analysis. Continued monitoring and community engagement will be essential to refine the benchmark and address such limitations over time.
What Comes Next
The LiveClin team is committed to maintaining the benchmark through biannual updates, ensuring its continued relevance and resistance to contamination. They also plan to explore ways to further broaden the diversity of case sources and incorporate feedback from the medical AI development community.
Ultimately, LiveClin represents a crucial step towards building trustworthy medical AI systems. By providing a continuously evolving, clinically grounded evaluation framework, it aims to drive the field towards closing the gap between leading models and expert-level clinical reasoning, paving the way for the safe and effective integration of these powerful tools into real-world healthcare.