Story
Just KIDDIN: Knowledge Infusion and Distillation for Detection of INdecent Memes
Key takeaway
Researchers developed a framework to better detect toxic content online by combining text and images, which could help make social media platforms safer for users.
Quick Explainer
The researchers proposed a hybrid approach called KID-VLM to detect toxicity in online memes. It combines knowledge distilled from large vision-language models with explicit relational semantics from knowledge graphs. This allows the model to capture both implicit and explicit contextual cues needed for accurate toxicity assessment. The key steps are: 1) distilling contextual knowledge from a large teacher model into a more compact student model, 2) infusing relational knowledge from a knowledge graph through graph-based reasoning, and 3) fusing the distilled multimodal representation with the graph-based representation. This knowledge-enhanced approach outperforms existing compact and large-scale models on benchmark toxicity detection tasks while maintaining an efficient model size.
Deep Dive
Technical Deep Dive: Just KIDDIN - Detecting INdecent Memes
Overview
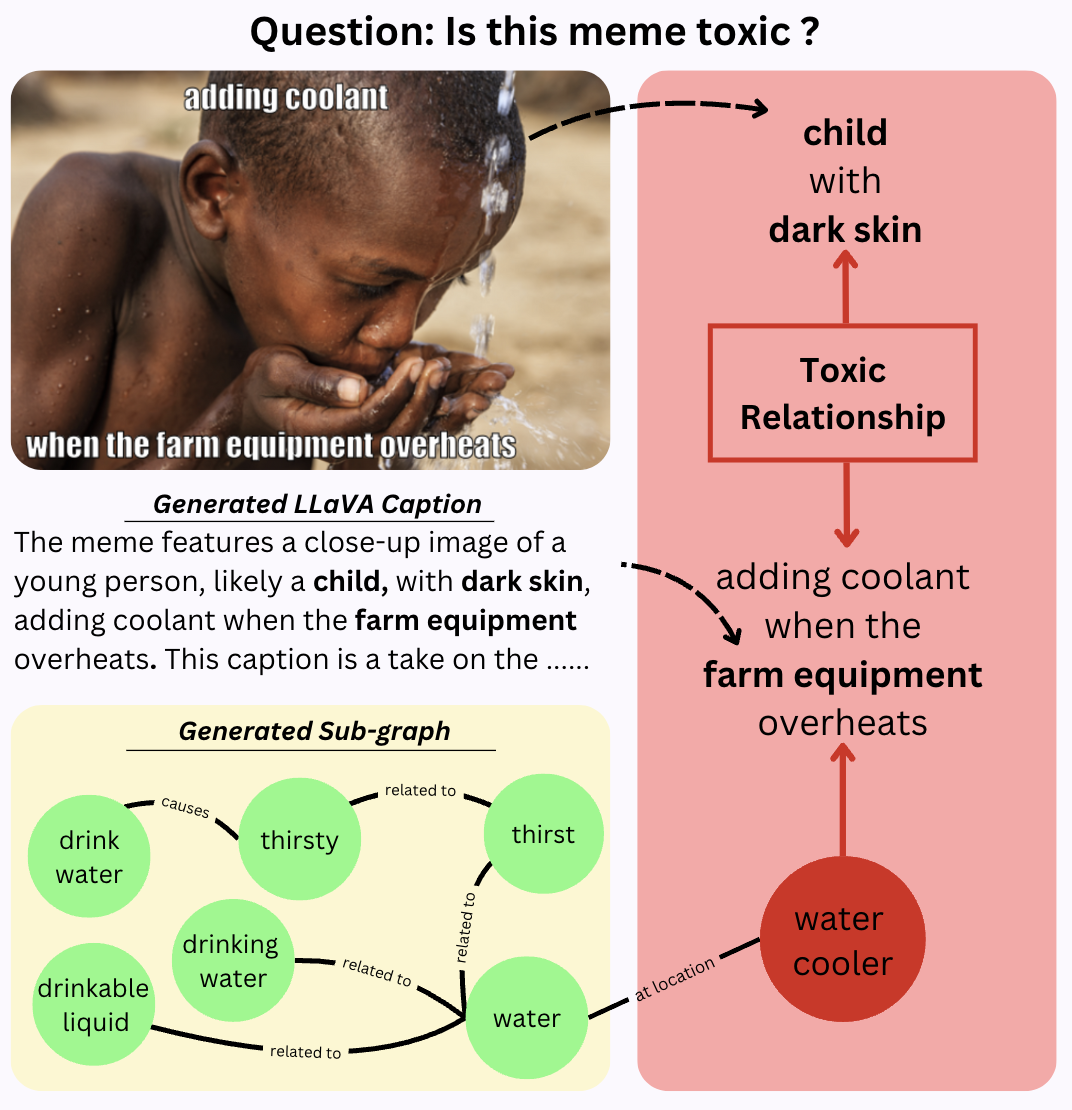
This work proposes a novel hybrid neurosymbolic framework, called Knowledge-Infused Distilled Vision-Language Model (KID-VLM), for detecting toxicity in online multimodal environments like memes. The key innovations are:
- Integrating implicit contextual knowledge distilled from Large Vision-Language Models (LVLMs) and explicit relational semantics infused from Knowledge Graphs (KGs) to enhance compact vision-language models.
- Utilizing CLIP as the backbone and LLaVA-NeXT for caption generation, followed by knowledge distillation and graph-based reasoning over ConceptNet to capture both implicit and explicit contextual cues.
- Achieving state-of-the-art performance on two benchmark datasets (HatefulMemes and HarMeme) while maintaining a compact model size (~500M parameters).
Problem & Context
- Online platforms have seen a surge in the dissemination of harmful, context-dependent content like memes, which can convey toxic messages through sarcasm, irony, or cultural references.
- Current methods rely solely on training data and pre-trained models, limiting their ability to capture complex contextual nuances required for accurate toxicity assessment.
- Large multimodal systems demand high computational resources, hindering their deployment in resource-constrained settings.
Methodology
- Knowledge Distillation (KD): Distill implicit contextual knowledge from the teacher model (LLaVA-NeXT) into the student model (CLIP-based) using a consistency loss.
- Knowledge Infusion (KI): Incorporate explicit relational knowledge from ConceptNet KG by constructing a joint working graph and applying Relational Graph Convolutional Network (R-GCN) for reasoning.
- Multimodal Fusion: Fuse the distilled multimodal representation and the graph-based representation using a Gated Fusion mechanism.
Data & Experimental Setup
- Evaluated on two benchmark datasets: HatefulMemes and HarMeme.
- Compared against compact VLMs like HateClipper, RGCL, Pro-Cap, and large models like MMBT, CLIP.
- Optimized hyperparameters using Optuna, including GNN architecture, fusion mechanisms, and loss weighting.
Results
- KID-VLM outperforms all baselines on both datasets:
- HatefulMemes: 10.6% improvement in F1 score and 0.5% in AUC on the unseen split.
- HarMeme: 6.3% improvement in F1 and 3.2% in AUC.
- The Hop 2 variant of KID-VLM shows the best overall performance, highlighting the benefits of broader contextual understanding.
- Ablation studies demonstrate the complementary benefits of KD and KI, with KID-VLM achieving the best results.
Interpretation
- Knowledge-enhanced representations lead to better separation between toxic and non-toxic content in the latent space, reducing ambiguity and misclassifications.
- KID-VLM's compact size (~500M parameters) enables efficient training and deployment, making it scalable for real-world toxicity detection applications.
- Multi-hop knowledge extraction helps the model generalize better, especially on unseen data, by capturing extended contextual cues.
Limitations & Uncertainties
- The model's reliance on ConceptNet may limit generalizability to datasets beyond the two examined.
- Graph-based methods can increase computational complexity, potentially affecting scalability for larger datasets.
- Potential for bias propagation from pre-trained models and KGs, as well as inherited hallucination issues from LLaVA.
What Comes Next
- Exploring more diverse datasets to assess the model's broader generalizability.
- Investigating strategies to improve scalability, such as more efficient graph reasoning approaches.
- Addressing potential biases through careful evaluation and the use of diverse data sources.
Sources: