Story
DIAGPaper: Diagnosing Valid and Specific Weaknesses in Scientific Papers via Multi-Agent Reasoning
Key takeaway
Researchers developed a system to automatically detect weaknesses in scientific papers, which could help improve the quality and reliability of published research.
Quick Explainer
DIAGPaper is a novel multi-agent framework that automatically identifies meaningful weaknesses in scientific papers. It models the key aspects of the human peer review process, such as decomposing the review criteria into specialized agents, facilitating an adversarial rebuttal between reviewers and authors, and prioritizing the most consequential weaknesses. By explicitly representing review criteria and incorporating adversarial interactions, DIAGPaper is able to surface valid, paper-specific critiques while filtering out invalid ones. This multi-agent approach enables DIAGPaper to outperform both general-purpose language models and prior review-focused systems, and to generalize effectively across diverse language model families.
Deep Dive
Technical Deep Dive: DIAGPaper
Overview
DIAGPaper is a novel multi-agent framework that automatically identifies valid and paper-specific weaknesses in scientific publications. It addresses key limitations of prior single-agent and multi-agent systems by:
- Explicitly modeling review criteria and instantiating specialized reviewer agents to assess different intellectual aspects of a paper.
- Incorporating an adversarial rebuttal mechanism between reviewer and author agents to filter out invalid or weakly supported critiques.
- Learning from large-scale human review practices to prioritize and surface the most consequential weakness issues.
The work makes three key contributions:
- Introduces DIAGPaper, a human-grounded multi-agent framework that achieves state-of-the-art performance on automatic weakness identification.
- Shows that DIAGPaper generalizes across diverse LLM families, elevating open-source models to levels approaching closed-source state-of-the-art.
- Provides detailed analyses elucidating the strengths and limitations of DIAGPaper and prior multi-agent review systems.
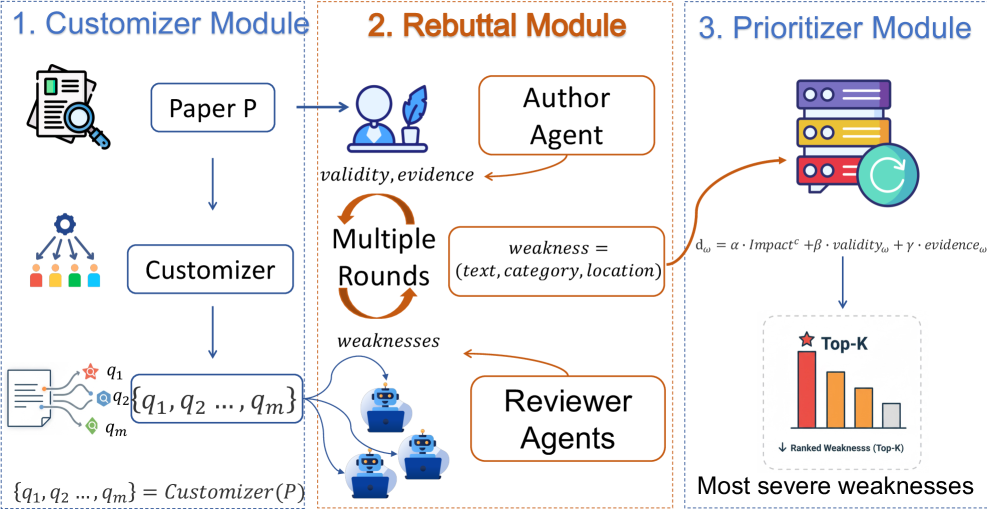
Methodology
The DIAGPaper system comprises three core modules:
Criteria-Oriented Reviewer Decomposition
- Crowdsources a set of 20 common review dimensions (e.g. dataset representativeness, experimental completeness, writing clarity) to instantiate specialized reviewer agents.
- Introduces a dedicated agent that dynamically generates paper-specific review dimensions, complementing the human-curated set.
Adversarial Interaction Between Reviewer and Author Agents
- Reviewer agents propose weaknesses specific to their assigned review dimension.
- An author agent then evaluates each proposed weakness, assessing its validity and the strength of paper-grounded evidence.
- This rebuttal mechanism filters out invalid or weakly supported critiques, retaining only well-justified weaknesses.
Outputting Top-K Severest Weaknesses
- Analyzes how different weakness categories propagate through real conference review processes to define a category-level "impact" score.
- Ranks validated weaknesses by a severity score that integrates the impact score, the validity assessment, and the evidence strength.
- Surfaces the top-K most consequential issues to users.
Results
- Achieves state-of-the-art performance on both semantic alignment with human reviews (F1) and the specificity of generated weaknesses across two benchmark datasets.
- Outperforms both general-purpose LLMs and review-specific agent systems.
- A key strength is its ability to reliably identify valid, paper-specific weaknesses while rejecting invalid critiques, as measured by the F1_inv metric.
- Analyses show the multi-agent framework consistently boosts performance across diverse LLM families, including elevating open-source models to near closed-source state-of-the-art levels.
- Human evaluation confirms that DIAGPaper surfaces novel yet reasonable weaknesses not previously identified by human reviewers.
Limitations
- The multi-agent architecture incurs higher runtime overhead, limiting its scalability for large-scale submission screening.
- The system does not explicitly retrieve external literature, focusing solely on assessing a paper's internal consistency and self-contained validity.
- Evaluation is limited to AI-related submissions, so the effectiveness on non-AI research domains remains unexplored.
Conclusion
DIAGPaper introduces a human-grounded, validity-oriented framework for automatically identifying consequential weaknesses in scientific publications. By modeling key review behaviors like criteria planning, reviewer-author rebuttal, and user-oriented prioritization, it achieves state-of-the-art performance and demonstrates robust generalization across LLM families.