Story
Retrieval Augmented Generation of Literature-derived Polymer Knowledge: The Example of a Biodegradable Polymer Expert System
Key takeaway
A new system can extract and combine information from polymer research papers to build better understanding of biodegradable plastics, which could lead to developing more sustainable materials.
Quick Explainer
The Polymer Literature Scholar aims to better leverage the vast, unstructured polymer science literature by developing two complementary retrieval-augmented generation (RAG) pipelines. The vector-based VectorRAG approach uses semantic embeddings and similarity search to retrieve relevant scientific context, while the graph-based GraphRAG constructs a structured knowledge graph to retrieve coherent subgraphs. Both pipelines outperform general-purpose systems, with GraphRAG providing higher precision and interpretability, and VectorRAG offering broader recall. This tailored approach to polymer literature leverages the field's unique structure and reporting conventions to generate well-grounded, citation-backed responses that can support scientific reasoning and knowledge synthesis.
Deep Dive
Technical Deep Dive: Retrieval Augmented Generation of Literature-derived Polymer Knowledge
Overview
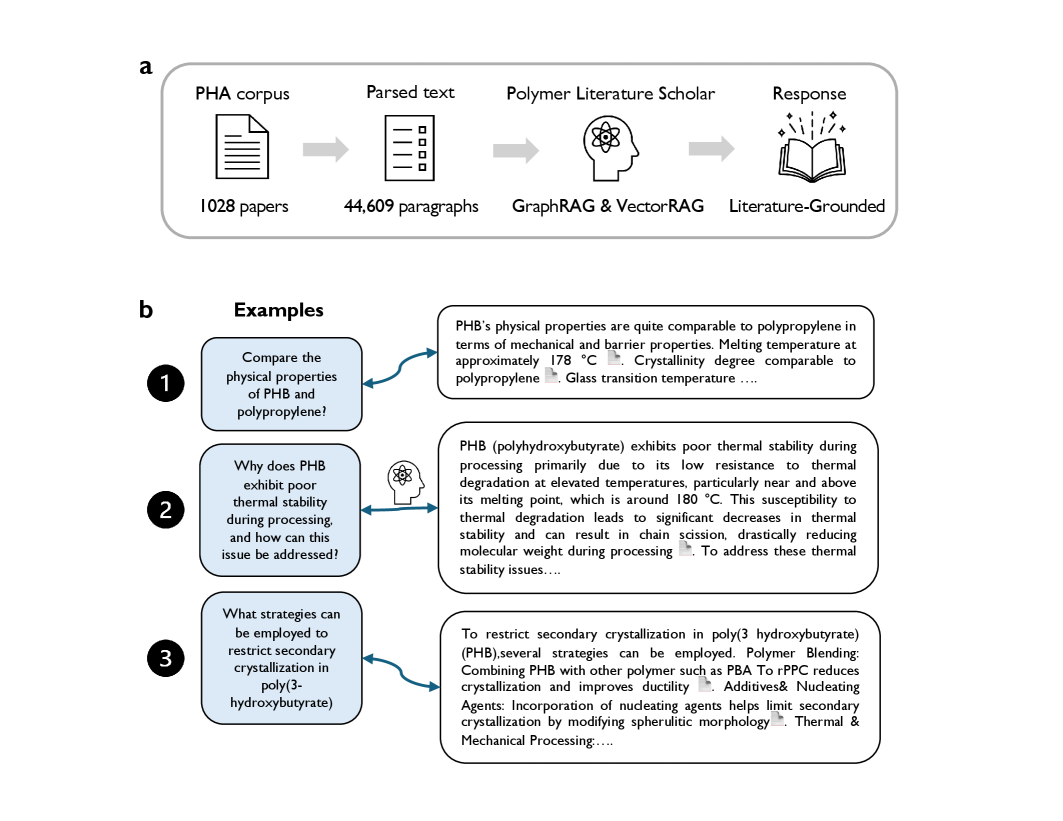
This work introduces the "Polymer Literature Scholar", a retrieval-augmented system designed to support literature-grounded reasoning for polymer science. It develops and benchmarks two complementary retrieval pipelines - a dense semantic vector-based approach (VectorRAG) and a structured graph-based approach (GraphRAG) - using a curated corpus of over 1,000 polyhydroxyalkanoate (PHA) papers.
Problem & Context
- Polymer science literature is vast, heterogeneous, and largely unstructured, making it difficult to retrieve, integrate, and use for scientific reasoning.
- Existing tools often extract narrow, study-specific facts without providing the integrated context needed to answer cross-cutting scientific questions.
- Retrieval-augmented generation (RAG) offers a promising approach, but its effectiveness depends on how domain knowledge is represented.
Methodology
Corpus Construction
- The literature corpus comprises ~3 million materials science documents, from which a PHA-specific subset of 1,028 papers was extracted and parsed.
- Paragraphs were extracted from the full-text articles for downstream processing.
VectorRAG Pipeline
- Uses dense semantic embeddings and similarity search to retrieve relevant paragraphs.
- Leverages a domain-aware text chunking strategy to preserve scientific context.
GraphRAG Pipeline
- Constructs a canonicalized knowledge graph from the corpus, with entities, relations, and citations.
- Retrieves relevant subgraphs through a hybrid of string-based and embedding-based matching, followed by context-aware re-ranking.
Evaluation
- Benchmark using Recall@K, Recall PID@K, and Accuracy evaluated by domain experts.
- Compare against state-of-the-art systems like GPT and Gemini.
Results
- GraphRAG achieves higher precision and interpretability, while VectorRAG provides broader recall.
- Both pipelines outperform general-purpose systems on domain-specific questions.
- Expert validation confirms the systems produce well-grounded, citation-reliable responses with high relevance.
Interpretation
- Tailoring retrieval to the structure and reporting conventions of polymer literature is crucial for reliable, trustworthy knowledge synthesis.
- Complementary vector-based and graph-based approaches leverage different strengths to address a range of scientific queries.
- Grounding model outputs in explicit source evidence enhances transparency and enables researchers to assess credibility.
Limitations & Uncertainties
- The work focuses on PHAs as a representative case study; further evaluation is needed to generalize the approach to other polymer domains.
- While the benchmark covers a range of query types, real-world scientific inquiries may introduce additional complexities.
- Expert evaluation, while valuable, relies on subjective judgments and may not capture all nuances of scientific reasoning.
What Comes Next
- Explore further enhancements to the retrieval pipelines, such as integrating interactive clarification of user queries.
- Expand the corpus to cover a broader range of polymer systems and scientific disciplines.
- Investigate methods for automatically identifying gaps or inconsistencies in the literature based on the system's outputs.
Sources: