Story
Discovering Multiagent Learning Algorithms with Large Language Models
Key takeaway
Researchers used large language models to discover new algorithms for training AI agents to cooperate and compete in complex, uncertain environments, which could lead to AI systems that can more effectively solve real-world problems.
Quick Explainer
This work proposes automating the design of multi-agent learning algorithms by applying Large Language Model-driven evolutionary search. The authors showcase this approach by discovering two novel algorithms: VAD-CFR, an evolved variant of Counterfactual Regret Minimization that uses non-intuitive mechanisms like volatility-adaptive discounting and asymmetric instantaneous regret boosting; and SHOR-PSRO, an evolved meta-strategy solver for Policy Space Response Oracles that dynamically transitions from exploration-oriented to exploitation-oriented behavior. The key innovation is using LLMs as intelligent genetic operators to mutate baseline algorithms, allowing the search to transcend simple parameter tuning and discover entirely new equilibrium-finding mechanisms that outperform manually designed baselines.
Deep Dive
Technical Deep Dive: Discovering Multiagent Learning Algorithms with Large Language Models
Overview
This work proposes a framework for automating the design of multi-agent learning algorithms by applying Large Language Model (LLM)-driven evolutionary search. The authors showcase this approach by discovering two novel algorithms:
- VAD-CFR: An evolved variant of Counterfactual Regret Minimization (CFR) that uses non-intuitive mechanisms like volatility-adaptive discounting, asymmetric instantaneous regret boosting, and regret-magnitude-weighted warm-start policy accumulation.
- SHOR-PSRO: An evolved meta-strategy solver for Policy Space Response Oracles (PSRO) that dynamically transitions from exploration-oriented to exploitation-oriented behavior during training.
Problem & Context
Multi-Agent Reinforcement Learning (MARL) has achieved significant milestones in complex domains like Poker and real-time strategy games. These advances have relied heavily on specific structural choices in game-theoretic regret minimization algorithms (e.g. CFR) and population-based training approaches (e.g. PSRO). Historically, refining these choices has been a manual, intuition-driven process.
The authors propose to automate this algorithm design process using LLM-driven evolutionary search, shifting from heuristic tuning to symbolic code evolution.
Methodology
The authors apply the AlphaEvolve framework, which uses LLMs as intelligent genetic operators to mutate the source code of baseline algorithms. This allows the search to transcend simple parameter tuning and discover entirely new mechanisms for equilibrium finding.
The search space is defined by exposing the core update functions of CFR and the meta-strategy solvers of PSRO to the evolutionary process.
Data & Experimental Setup
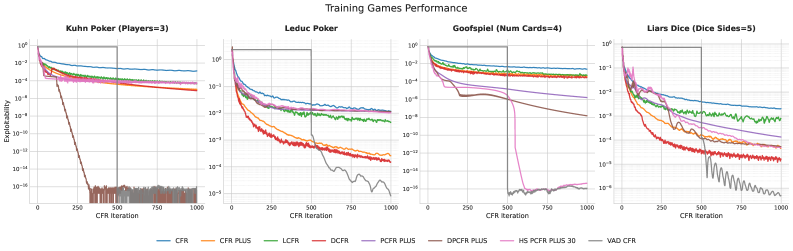
The authors evaluate the discovered algorithms on a Training Set of 4 games (3-player Kuhn Poker, 2-player Leduc Poker, 4-card Goofspiel, 5-sided Liars Dice) and a Test Set of 4 larger, more complex games (4-player Kuhn Poker, 3-player Leduc Poker, 5-card Goofspiel, 6-sided Liar's Dice).
Exploitability, measured as the average incentive for players to deviate, is used as the primary performance metric.
Results
VAD-CFR
- Discards standard linear averaging and static discounting in favor of 3 non-intuitive mechanisms:
- Volatility-Adaptive Discounting: Dynamically adjusts discounting based on regret update volatility
- Asymmetric Instantaneous Boosting: Amplifies positive instantaneous regrets
- Hard Warm-Start & Regret-Magnitude Weighting: Delays policy averaging until iteration 500, weighting by regret magnitude
- Outperforms state-of-the-art baselines like DCFR and PCFR+ on the training set
- Generalizes well, matching or exceeding baselines on the larger test games
SHOR-PSRO
- Employs a "Hybrid" meta-solver that linearly blends Optimistic Regret Matching and a Smoothed Best Pure Strategy
- Uses a dynamic annealing schedule, gradually shifting from exploration to exploitation
- Distinct training-time and evaluation-time configurations, allowing safe exploration during training
- Outperforms standard meta-solver baselines like Uniform, Nash, PRD, and Regret Matching on both the training and test sets
Interpretation
The authors demonstrate that automated discovery via LLM-driven evolution can uncover complex, non-intuitive algorithmic mechanisms that outperform manually designed baselines. The evolved VAD-CFR and SHOR-PSRO variants highlight how filtering out noise, managing regret scaling, and dynamically transitioning exploration-exploitation can yield significant performance gains.
This work suggests that future game-theoretic solvers will likely derive from a blend of human ingenuity and AI-driven insights, as the combinatorial design space becomes too complex for manual tuning alone.
Limitations & Uncertainties
- The paper focuses on exact exploitability computation, which limits scalability to larger games. Extending the analysis to approximation metrics would broaden the applicability.
- The evolutionary process and discovered algorithms are tightly coupled to the specific problem formulation and evaluation games. Generalizing the framework to other multi-agent learning domains requires further investigation.
- While the authors provide high-level algorithmic descriptions, the full implementation details of VAD-CFR and SHOR-PSRO are not included, limiting reproducibility.
What Comes Next
Future work could explore:
- Applying the evolutionary framework to fully deep reinforcement learning agents
- Discovering cooperative mechanisms in general-sum games
- Expanding the automated discovery process to other multi-agent learning domains beyond game-theoretic solvers
Sources: