Story
FairTabGen: High-Fidelity and Fair Synthetic Health Data Generation from Limited Samples
Key takeaway
Researchers developed a tool called FairTabGen that can create realistic synthetic health data without private patient information, enabling medical research while protecting privacy.
Quick Explainer
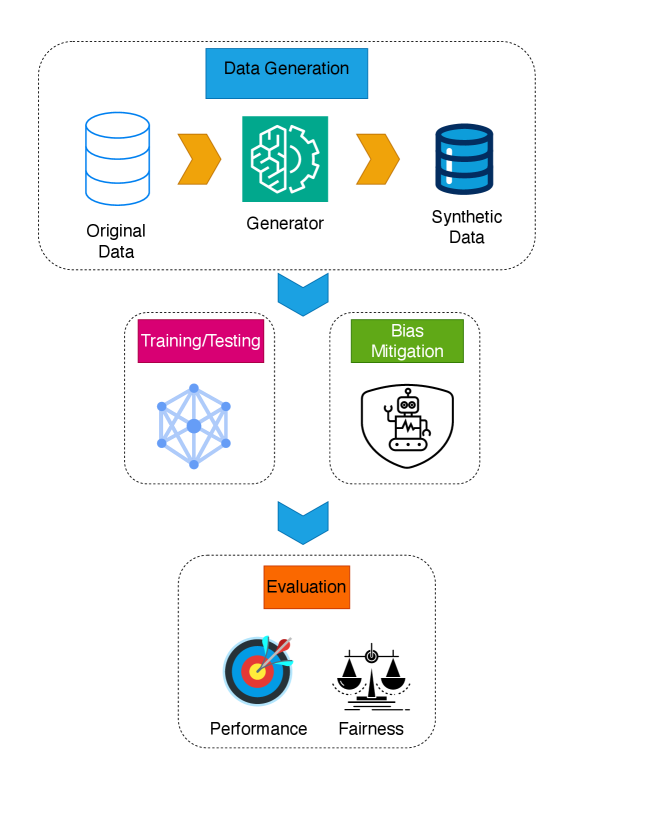
FairTabGen generates high-quality synthetic healthcare data that retains predictive utility while improving fairness across sensitive attributes like race and gender. It uses a prompt-based framework with large language models to produce synthetic samples, incorporating constraints to ensure fairness. The approach involves curating and preprocessing the source dataset, generating synthetic data with utility and fairness in mind, evaluating the generated data, and applying targeted bias mitigation techniques. This novel combination of prompt-guided data synthesis and selective bias reduction enables FairTabGen to create fair, representative synthetic healthcare datasets from limited real-world samples.
Deep Dive
Technical Deep Dive: FairTabGen for Fair Synthetic Healthcare Data Generation
Overview
FairTabGen is a method for generating high-fidelity and fair synthetic healthcare data from limited samples. It leverages large language models (LLMs) and prompt curation to produce synthetic data that retains predictive utility while improving fairness across sensitive attributes like race and gender. Key contributions include:
- A prompt-based framework for tabular data synthesis that incorporates utility and fairness constraints without extensive fine-tuning.
- Evaluation on the MIMIC-IV dataset showing 50% fairness improvement using 99% less source data while maintaining competitive predictive performance.
- Application of pre-processing bias mitigation techniques to further enhance fairness.
Problem & Context
Real-world healthcare datasets often exhibit systemic biases due to factors like limited access and use of biased clinical proxies. While high predictive performance is common, it does not guarantee equitable outcomes across demographic groups. There is a need for approaches that can generate synthetic data that is both high-fidelity and fair.
Methodology
FairTabGen uses a modular, iterative framework with four key stages:
- Data Curation & Preprocessing: The MIMIC-IV dataset is used, with 200 seed samples extracted and missing values imputed.
- Fairness-Aware Synthetic Data Generation: A structured prompt is used to guide an LLM in generating synthetic data samples, incorporating utility and fairness constraints.
- Utility and Fairness Evaluation: Synthetic data is evaluated for predictive performance (precision, recall, AUROC) and fairness (fairness through unawareness, demographic parity).
- Bias Mitigation: Pre-processing techniques like suppression, correlation removal, disparate impact removal, and reweighing are applied to further improve fairness.
Results
Compared to the original MIMIC-IV dataset and other baselines:
- FairTabGen achieves 50% improvement in fairness through unawareness and demographic parity, using 99% less source data.
- Predictive performance (AUROC) remains competitive at 0.644.
- Applying bias mitigation techniques further reduces the gap in true positive rate difference and error rate difference between demographic groups.
Interpretation
FairTabGen demonstrates that high-quality synthetic healthcare data can be generated using a small subset of the original dataset, while maintaining fairness across sensitive attributes. The use of prompt-based LLM generation and targeted bias mitigation techniques enable this balance of utility and fairness. However, the skewed racial distribution in the original MIMIC-IV data is reflected in the synthetic samples, which may limit the generalizability of these findings.
Limitations & Uncertainties
- The racial distribution in the synthetic data mirrors the skewed representation in the original MIMIC-IV dataset.
- Reliance on the black-box GPT-4o model limits reproducibility and interpretability in clinical settings.
- The evaluation is limited to a single healthcare dataset and outcome, and may not generalize to other domains or tasks.
Next Steps
To address these limitations, future work should:
- Evaluate FairTabGen on more diverse healthcare datasets to assess robustness.
- Incorporate open-source language models to improve transparency and enable wider adoption.
- Explore techniques to actively debias the data distribution during the generation process.
- Expand the evaluation to include a broader set of fairness and utility metrics.
By addressing these areas, FairTabGen can be further refined into a more extensible and trustworthy framework for generating fair synthetic healthcare data.